Configuring Clusters
Every new account is configured with some clusters by default; these are sufficient to run small test workloads. This section and Managing Clusters explain how to modify these default clusters and add and modify new ones:
Cluster Settings Page
To use the QDS UI add or modify a cluster, choose Clusters from the drop-down list on the QDS main menu, then choose New and the cluster type and click on Create, or choose Edit to change the configuration of an existing cluster.
See Managing Clusters for more information.
The following sections explain the different options available on the Cluster Settings page.
General Cluster Configuration
Many of the cluster configuration options are common across different types of clusters. Let us cover them first by going over some of the most important categories.
Configuring Query Runtime Settings
Qubole supports the following options to control the query runtime for a given cluster that you can get enabled Via Support:
The configuration that sets the query execution timeout in minutes for a cluster. Qubole auto terminates a query if its runtime exceeds the timeout.
The configuration that sets a warning about the query runtime in minutes for a given cluster. Qubole notifies you through an email if a query’s runtime exceeds the configured time.
The configuration that enables sending notification to users on the query runtime. This configuration is also enabled at the account level, which is a self-service configuration as described in Configuring your Account Settings. The warning notification set for a cluster has precedence over the notification frequency configured at the account level.
Note
If the account-level or cluster-level configuration for receiving email notifications are not set, then a user does not receive email/warning notifications.
Cluster Labels
As explained in Cluster Labels, each cluster has one or more labels that are used to route Qubole commands. In the first form entry, you can assign one or more comma-separated labels to a cluster.
Cluster Type
QDS supports the following cluster types:
Airflow (not configured by default).
Airflow is a platform for programmatically authoring, scheduling, and monitoring workflows. It supports integration with third-party platforms. You can author complex directed acyclic graphs (DAGs) of tasks inside Airflow. It comes packaged with a rich feature set, which is essential to the ETL world. The rich user interface and command-line utilities make it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues as required. To know more about Qubole Airflow, see Airflow.
Hadoop 2 (one Hadoop 2 cluster is configured by default in all cases).
Hadoop 2 clusters run a version of Hadoop API compatible with Apache Hadoop 2.6. Hadoop 2 clusters use Apache YARN cluster manager and are tuned for running MapReduce and other applications.
Presto (one Presto cluster is configured by default on Cloud platforms that support Presto; see QDS Components: Supported Versions and Cloud Platforms).
Presto is the fast in-memory query processing engine from Facebook. This is useful for near-real-time query processing for less complex queries that can be mostly performed in-memory.
Spark (one Spark cluster is configured by default in all cases).
Spark clusters allow you to run applications based on supported Apache Spark versions. Spark has a fast in-memory processing engine that is ideally suited for iterative applications like machine learning. Qubole’s offering integrates Spark with the YARN cluster manager.
Spark Streaming
Spark Streaming clusters are required to run Spark structured streaming pipelines at scale with the Quest features. These clusters support scalable and fault-tolerant spark engine.
Spark Streaming clusters have the following features enabled by default:
Disable Time-out for Long Running Tasks: Qubole has a 36-hour time limit on every command run. Streaming jobs might wait for events to arrive, and therefore, should not be killed/timed out.
Enable Log Rolling: The logs for running streaming applications are rolled and aggregated periodically into the remote storage S3, to prevent hard disk space issues.
Out of the Box Monitoring: With Promethues, you can view job status in real-time from the Quest UI or from the Clusters page.
Spark Streaming clusters are visible only through the Quest UI.
Cluster Size and Instance Types
From a performance standpoint, this is one of the most critical sets of parameters:
Set a Minimum and Maximum Worker Nodes for a cluster (in addition to one fixed Coordinatorr node).
Note
All Qubole clusters autoscale up and down automatically within the minimum and maximum range set in this section.
Coordinator and Woker Node Type
Select the Worker Node Type according to the characteristics of the application. A memory-intensive application would benefit from memory-rich nodes (such as r3 node types in AWS, or E2-64 V3 in Azure), while a CPU-intensive application would benefit from instances with higher compute power (such as the c3 types in AWS or E2-64 V3 in Azure).
The Coordinator Node Type is usually determined by the size of the cluster. For smaller clusters and workloads, small instances (such as m1.large in AWS or Standard_A6 in Azure) suffice. But for extremely large clusters (or for running a large number of concurrent applications), Qubole recommends large-memory machines (such as 8xlarge machines in AWS, or larger Azure instances such as Standard_A8).
QDS uses Linux instances as cluster nodes.
Node Bootstrap File
This field provides the location of a Bash script used for installing custom software packages on cluster nodes.
Advanced applications often require custom software to be installed as a prerequisite. A Hadoop Mapper Python script may require access to SciPy/NumPy, for example, and this is often best arranged by simply installing these packages (using yum for example) by means of the node bootstrap script. See Understanding a Node Bootstrap Script for more information.
The account’s storage credentials are used to read the script, which runs with root privileges on both Coordinator and worker nodes; on worker nodes, make it runs before any task is launched on behalf of the application.
Note
QDS does not check the exit status of the script. If software installation fails and it is unsafe to run user applications in this case, you should shut the machine down from the bootstrap script.
Qubole recommends installing or updating custom Python libraries after activating Qubole’s Virtual Environment and installing libraries in it.
See Running Node Bootstrap and Ad hoc Scripts on a Cluster for more information on running node bootstrap scripts.
Other Settings
See Managing Clusters.
AWS Settings
QDS clusters optimize Cloud usage costs, taking advantage of cheaper instances on the AWS Spot market. This section covers the relevant settings. See also Using AWS Spot Instances and Spot Blocks in QDS Clusters and Autoscaling in Qubole Clusters.
Configure the following in the Cluster Composition section:
Coordinator and Minimum Worker Nodes: Specifies the AWS purchasing model for the Coordinator node and the minimum set of nodes that run while the cluster is up. Qubole recommends using On-Demand instances for these nodes.
Autscaling Worker Nodes: Specifies the AWS purchasing model for worker nodes added to and removed from the cluster during autoscaling. Possible values are:
On-Demand Instance: Qubole recommends this setting for workloads that are not cost sensitive or are extremely time sensitive.
Spot Instance: When you choose to use Spot Nodes, QDS bids for Spot instances when provisioning autoscaling nodes.
Use Qubole Placement Policy: When worker nodes are Spot instances, this policy makes a best effort to ensure that at least one replica of each HDFS block is placed on on a stable instance. Qubole recommends you leave this enabled.
Fallback to On-demand Nodes: Enable this to prevent data loss that could occur if QDS cannot procure Spot instances, or AWS reclaims them while the cluster is running. This option specifies that in this case QDS should procure On-Demand instances instead. QDS attempts to replace these On-Demand instances with Spot instances as soon as suitable instances become available.
Maximum Price Percentage: Specifies the maximum bid price for the autoscaling Spot nodes, as a percentage of On-Demand Instance price.
Request Timeout: Specifies the time in minutes for which the bid is valid. Set this to one minute.
Spot Nodes %: Specifies the maximum percentage of autoscaling nodes that can be Spot instances. For example, if the cluster has a minimum size of 2 nodes, a maximum size of 10, and a Spot percentage of 50%, then while scaling the node from 2 to 10 nodes, QDS tries to use 4 On-Demand and 4 Spot nodes.
AWS EC2 Settings
See also Advanced Configuration: Modifying Security Settings (AWS).
Qubole Public Key cannot be changed. QDS uses this key to access the cluster and run commands on it.
Persistent Security Groups - This option overrides the account-level security group settings. By default, this option is not set; it inherits the account-level persistent security group, if any. Use this option if you want to apply additional access permissions to cluster nodes. You must provide a persistent security group when you configure outbound communication from cluster nodes to pass through a Internet proxy server.
AWS Region and Availability Zone can be selected for nodes in the cluster.
By default, the Region is set to us-east-1. If it is set to No Preference, the best Availability Zone based on system health and available capacity is selected. Note that all cluster nodes are in the same availability zone. You can select an Availability Zone in which instances are reserved to benefit from the AWS Reserved Instances. However, if the cluster is in a VPC, then you cannot set the AZ.
VPC and Subnet settings can be used to launch this cluster within a specific VPC.
If they are not specified, cluster nodes are placed in a Qubole created Security Group in EC2-Classic or in the default VPC for EC2-VPC accounts.
Custom EC2 Tags allow you to tag instances of a cluster and EBS volumes attached to these instances to get that tag on AWS. They are useful in billing across teams as you get the AWS cost per tag, which helps to calculate the AWS costs of different teams in a company. This setting is under the Advanced Settings tab. These tags are applied to the Qubole-created security groups (if any).
AWS EBS Volumes
EBS Volume settings allow you to add additional EBS drives to AWS instances when they are launched.
These options are displayed only for instances with limited instance-store capacity (such as c3 instance types).
Additional drives may not be required if jobs do not generate a lot of output, so use this option only if your testing shows you need it.
QDS uses instance-store drives in preference to EBS volumes even if the latter are configured. This is only valid to magnetic EBS volumes on Hadoop clusters. This reduces AWS cost and helps to achieve better and more predictable I/O performance.
Qubole has the following recommendations for using EBS volumes:
If workflows use HDFS intensively, it is recommended to use
st1volumes. EBS upscaling may also be enabled in such cases to avoid out of space errors.For instance types that do not have any instance store volumes (
m4,c4, andr4), it is recommended to use at least two EBS volumes as one disk would also be used for logs and other frequently-accessed data and it may thus experience reduced bandwidth for HDFS.In other cases, small SSD volumes should suffice.
It is not recommended to use older generation magnetic (standard) volumes as they are comparatively poor in performance and unlike other volume types, there is an additional charge by AWS on I/O to these volumes.
ssd,st1, andsc1volumes operate on a burst capacity model as described here. Hence, if the desired disk capacity is between 2 and 12.5 TB, it is preferable to use multiple smaller disks (of 2 TB or above) since you would get more burst capacity. However if you are using less than that you are better off with a singlest1volume. Between 12.5 and 16 TB, you do not get any benefit of the burst capacity. Similarly for SSD volumes up to 1 TB, it is better to use multiple smaller volumes so you can make use of more burst capacity. However, it is not recommended to use too small a volume size since the baseline IOPS would be very low. Also, the burst capacity would be exhausted quite quickly and would take a longer time to refill. Above 1 TB, you would not get the benefit of burst capacity, so it is better to use a single volume so you can use the higher baseline throughput.Note
If you need more than 1 TB HDFS capacity per node, it would be better to use
st1volumes instead ofssdvolumes for better throughput and cheaper cost.
See Cluster Configuration Settings (AWS) for more information on the supported EBS Volume Type and the size range.
Qubole has added support to use EBS disk size proportional to the node weight in heterogeneous clusters. This enhancement is part of Gradual Rollout. When this enhancement is enabled, the EBS disk size that you specify in the Clusters configuration on the UI is with respect to the base worker type. For the remaining instance types in the heterogeneous configuration, Qubole multiplies this EBS disk size with the node weight (ratio of memory with respect to the base instance type).
Configuring EBS Upscaling in AWS Hadoop and Spark Clusters
EBS upscaling is supported on YARN-based clusters: Hadoop 2 (Hive) and Spark clusters. QDS dynamically scales cluster storage (independent of compute capacity) to suit the workload by adding EBS volumes to EC2 instances that have limited storage and are close to full capacity. EBS upscaling is available only on instance types on which Qubole supports adding EBS storage. See EBS Upscaling on Hadoop MRv2 AWS Clusters for more information.
EBS upscaling is not enabled by default; you can enable it for Spark and Hadoop 2 clusters in the Clusters section of the QDS UI, or use the Clusters API. For the required EC2 permissions, see Sample Policy for EBS Upscaling..
To enable EBS upscaling in the QDS UI, choose a value greater than 0 from the drop-down list for EBS Volume Count. Then you can select Enable EBS Upscaling. Once you select it, the EBS upscaling configuration is displayed with the default configuration as shown in this figure.
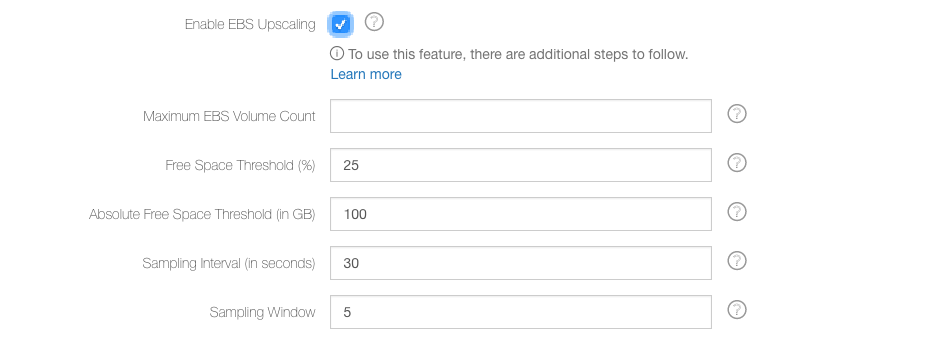
You can configure:
The maximum number of EBS volumes QDS can add to an instance: Maximum EBS Volume Count. It must be more than the EBS volume count for the upscaling to work.
The percentage of free space on the logical volume as a whole at which disks should be added: Free Space Threshold. The default is 25%, which means new disks are added when the EBS volume is at least 75% full. The percentage threshold changes as the size of the logical volume increases. For example, if you start with a threshold of 15% and a single disk of 100GB, the disk would upscale when it has less than 15GB free capacity. On addition of a new node, the total capacity of the logical volume becomes 200GB and it would upscale when the free capacity falls below 30GB.
The free-space capacity (in GB) above which upscaling does not occur: Absolute Free Space Threshold. The default is 100 GB. If you prefer to upscale only when free capacity is below a fixed value, use the Absolute Free Space Threshold. The default value is 100, meaning that if the logical volume has at least 100GB of capacity, QDS does not add more EBS volumes.
The frequency (in seconds) at which the capacity of the logical volume is sampled: Sampling Interval. The default is 30 seconds.
The number of sampling intervals over which Qubole evaluates the rate of increase of used capacity: Sampling Window. The default is 5. It is the number of Sampling Intervals over which Qubole evaluates the rate of increase of used capacity. Its default value is 5. This means that the rate is evaluated over 150 (30 * 5) seconds by default. To disable upscaling based on rate and use only thresholds, this value may be set to 1. When the rate-based upscaling is set to 1, then Absolute Free Space Threshold is monitored at Sampling Interval.
The logical volume is upscaled if, at the current rate of usage, it will fill up in (Sampling Interval + 600) seconds (the additional 600 seconds is because the addition of a new EBS volume to a heavily loaded volume group has been observed to take up to 600 seconds).
Here is an example of how the free space threshold decreases with respect to the Sampling Window and Sampling Interval. Assuming the default value of Sampling Interval (30 seconds) and Sampling Window (5), this is how the free space threshold decreases:
0th second: 100% free space
30th second: 95.3% free space
60th second: 90.6% free space
90th second: 85.9% free space
120th second: 81.2% free space
150th second: 76.5% free space
180th second: 71.8% free space
210th second: 67.1% free space
…
…
…
600th second: 6% free space
630th second: 1.3% free space
ebs_upscaling_config provides a list of API parameters related to EBS upscaling configuration.
Miscellaneous AWS Cluster Settings
Enable Encryption:
If you select this option, the HDFS file system and intermediate output generated by Hadoop are stored in an encrypted form on local storage devices. Block device encryption is set up for local drives before the node joins the cluster. As a side effect, the cluster might take additional time (depending on the instance type selected) before it becomes operational. Upscaling a cluster may also take longer.
Azure Settings
To use the QDS UI to add or modify an Azure cluster, choose Clusters from the drop-down list on the QDS main menu, then choose New and the cluster type and click on Create, or choose Edit to change the configuration of an existing cluster. Configure the cluster as described under Modifying Cluster Settings for Azure.
Oracle OCI Settings
To add or modify an Oracle OCI cluster, choose Clusters from the drop-down list on the QDS main menu, then choose New, or choose Edit to change the configuration of an existing cluster. Then follow the directions you used when you first updated your clusters.
Oracle OCI Classic Settings
To add or modify an Oracle OCI Classic cluster, choose Clusters from the drop-down list on the QDS main menu, then choose New, or choose Edit to change the configuration of an existing cluster. Then follow the directions you used when you first updated your clusters.
Hadoop Settings
See Advanced Configuration: Modifying Hadoop Cluster Settings.