Configuring S3/Azure Blob Storage Files Data Dependency¶
S3 or Azure blob storage files’ dependency implies that a schedule runs if the data is available in S3 buckets or Azure blob storage. You can create a schedule to run at a specific date and time, either once or on a repetitive basis if the data exists. You can define repeat intervals such as last 6 hours, last 6 days, last 3 weeks, and last 7 months.
To create a schedule at periodic intervals, Qubole Scheduler requires the following information:
- Start day or time (parameter: window_start)
- End day or time (parameter: window_end)
- Day or time interval that denotes when and how often data is generated (parameter: interval)
- Nominal time which is the logical start time of an instance
For AWS: The following table shows how to create data in S3 files for the previous day’s data with daily interval.
| Sequence ID | Nominal Time | Created At | Dependency |
|---|---|---|---|
| 1 | 2015-01-01 00:00:00 | 2015-04-22 10:00:00 | s3://abc.com/data/schedule-2014-12-31-00-00-00 |
| 2 | 2015-01-02 00:00:00 | 2015-04-22 10:15:00 | s3://abc.com/data/schedule-2015-01-01-00-00-00 |
| 3 | 2015-01-03 00:00:00 | 2015-04-22 10:30:00 | s3://abc.com/data/schedule-2014-01-02-00-00-00 |
For Azure: The following table shows how to create data in Azure blob storage files for the previous day’s data with daily interval.
| Sequence ID | Nominal Time | Created At | Dependency |
|---|---|---|---|
| 1 | 2015-01-01 00:00:00 | 2015-04-22 10:00:00 | wasb://abc.com/data/schedule-2014-12-31-00-00-00 |
| 2 | 2015-01-02 00:00:00 | 2015-04-22 10:15:00 | wasb://abc.com/data/schedule-2015-01-01-00-00-00 |
| 3 | 2015-01-03 00:00:00 | 2015-04-22 10:30:00 | wasb://abc.com/data/schedule-2014-01-02-00-00-00 |
Nominal Time is the time when the next instance of the schedule is picked and Created At is the time at which the Scheduler picked up the schedule. For more information, see Understanding the Qubole Scheduler Concepts.
To configure S3 or Azure blob storage files dependency, select the Wait For S3 Files or Wait for files from Azure blob storage option available in Dependencies.
Note
Use the tooltip  to know more information on each field or check box.
to know more information on each field or check box.
The following steps explain how to set S3 or Amazon blob storage File dependency:
Enter the S3 or Azure blob storage location in the format:
s3://<bucket>/<folderinS3bucket>/<abc>-%Y-%m-%d-%H-%M-%Sorwasb://<bucket>/<folderinwasb>/<abc>-%Y-%m-%d-%H-%M-%S. For example:s3://abc.com/data/schedule-2014-12-31-00-00-00orwasb://abc.com/data/schedule-2014-12-31-00-00-00.Enter the value in the Done Flag field. The default value of this field is
_SUCCESS. You can change the value by rewriting. According to the entered value, QDS searches the file. For example, if you enterjob_completedas the Done Flag value, it searches fors3://abc.com/data/schedule-2014-12-31/job_completedorwasb://abc.com/data/schedule-2014-12-31/job_completed. If you enter/or leave it empty, it will search fors3://abc.com/data/schedule-2014-12-31/orwasb://abc.com/data/schedule-2014-12-31/.Enter the numerical value for the time interval corresponding to the file path in the Interval field.
Select a time unit in the Increment drop-down list for the time interval (for the Interval field).
Note
If you select Cron expression as the Frequency, it makes Interval and Increment fields manadatory for you. For more information on configuring the Frequency, see Setting Schedule Parameters.
Window Start and Window End defines the range of interval to wait for. The values are integers in units of time, hour/day/week/month/year.
Enter the Window Start value. See Hive Datasets as Schedule Dependency for more information on the window start parameter. An instance runs waits for files for the specified time range. Window Start specifies the start of this range. For example if you set -1 as window start time that implies 1 hour before/previous day/week/month/year. If it is 2 hour/day/week/month/year before, the value of window start is -2 and so on.
Note
Qubole Scheduler supports strife format and unpadded values for specifying months. For example, January can be specified as only
1and March can be specified as only3.Enter the Window End value. See Hive Datasets as Schedule Dependency for more information on the window end parameter. An instance runs waits for files for the specified time range. Window End specifies the end of this range. For example, if the interval is for 7 days and window start value is -6, the window end time is 0.
The value 0 implies now, -1 implies 1 day ago, and -2 implies 2 days ago. Correspondingly, for hourly/daily/weekly/monthly/yearly interval (frequency), the value 0 denotes now. -1 denotes 1 hour/day/week/month/year ago. -2 denotes 2 hour/day/week/month/year ago and so on.
Qubole Scheduler supports waiting for data. For example, waiting for 6 weeks of data implies that window_start is -5 and window_end is 0 when the frequency is weekly.
An example is illustrated in the following figure.
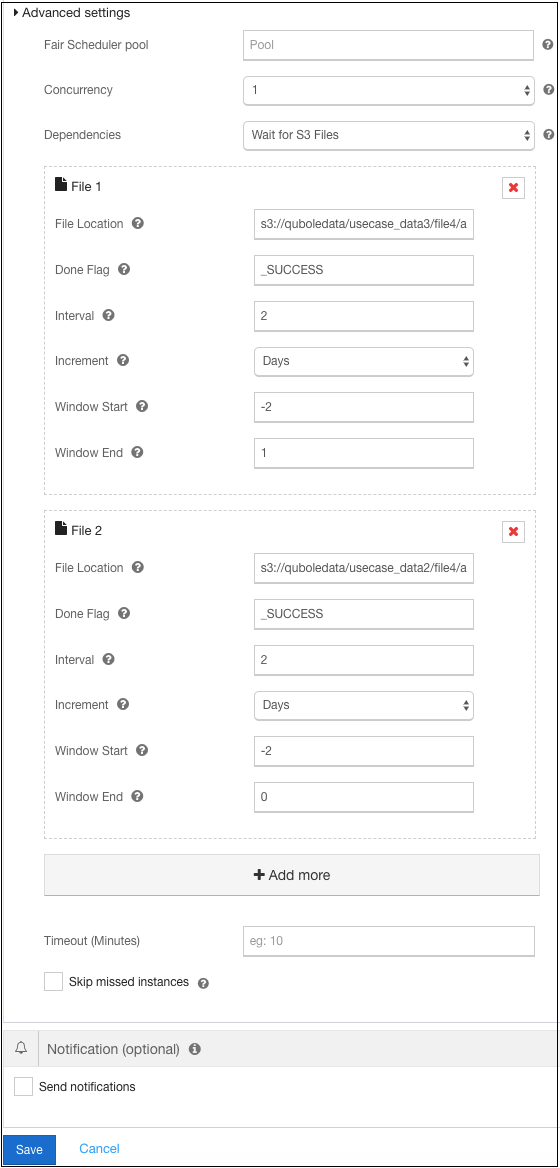
Configure Timeout in minutes to change the default/previously-set time.
Note
When the data arrival interval and the scheduler interval are different, then the scheduler interval follows its own frequency to process the data. For example, if the data arrival interval is hourly and the scheduler interval is daily, the scheduler waits for an entire day’s data.
Click +Add More to add a second file. Repeat steps 1-3 to enter the file details. Timeout is set only once as it is applicable to all files.
Click +Add More to add the number of files as per the periodicity/frequency of the schedule.