Understanding Aggressive Downscaling in Clusters (AWS)
Qubole has helped its customers in saving millions in cloud-infrastructure costs through autoscaling, spot instances, and cluster management features. On October 2, 2017, AWS launched Per Second Billing support for EC2 instances. In response to it, Qubole has announced aggressive downscaling for its customers starting from November 2017.
In addition, Qubole has undertaken numerous enhancements to its cluster management software to take advantage of the new AWS functionality to allow faster recycling of clusters and nodes. This can help customers further reduce the cost of running Big Data clusters in the AWS cloud. This topic aims at providing an overview of the first set of changes rolled out under the umbrella project of Aggressive Downscaling.
Enabling the Aggressive Downscaling Feature
This feature is only available on a request. Contact the account team to enable this feature on the QDS account.
Important details and caveats for different cluster types apply and are detailed in the rest of this topic.
Understanding the Changes that are in Aggressive Downscaling
The following new changes come into effect with Aggressive Downscaling:
Faster Cluster Termination: QDS waits for a configurable time period (called the Idle Cluster Timeout), after the last command execution, before terminating clusters. With the aggressive downscaling enhancements, QDS now allows configuring the Idle Cluster Timeout in minutes. For details see Understanding Changes in Cluster Termination.
Faster Node Termination: Earlier to aggressive downscaling changes, QDS used to wait for the hourly boundary before terminating a node in a QDS cluster (even if the node was otherwise idle). An hourly boundary denotes the default duration for which Qubole clusters try to run nodes, which is in multiples of one hour. This is no longer applicable and a node can now be terminated when it becomes idle.
Cool Down Period: Faster node termination can cause a cluster to rapidly fluctuate in size. This can both be inefficient (most of the node uptime can be spent in booting up) and bad for user experience (commands may have to wait for cluster upscaling all the time). With aggressive downscaling enhancements, Qubole introduces the notion of the cool down period, which is a configurable time period that determines how long QDS waits before terminating a cluster node after it is completely idle. For more information, see Cool Down Period.
In addition to these changes, Qubole gradually rolls out Container Packing to its entire customers alongside the aggressive downscaling enhancements. Container Packing is a new resource allocation strategy for YARN clusters (that is Hadoop and Spark Clusters in QDS) that makes more nodes available for downscaling in an elastic computing environment. For more information, see the blog post on Container Packing. While not a new feature per se, but this ensures that more nodes are available to downscale at any given time and that QDS clusters are more aggressively able to take advantage of the AWS per-second billing.
Note
The changes related to faster Node Termination, Cool Down Period, and Container Packing require a cluster restart to be effective. The changes related to faster Cluster Termination is effective after you enable Aggressive Downscaling for an account and reduce the timeout for faster cluster termination as the default timeout is still two hours.
Understanding Changes in Cluster Termination
This section describes the current behavior prior to aggressive downscaling and the behavior with aggressive downscaling enhancements.
Current Behavior without Aggressive Downscaling
If cluster auto-termination is enabled, QDS waits for the configured Idle Cluster Timeout before terminating clusters. Prior to aggressive downscaling enhancements, this value was always specified in hours with 2 hours as its default. The default setting of the timeout implied that Qubole would terminate a cluster only after no command has run on the cluster in the last two hours. After this criteria is met, Qubole terminates the cluster if there is any node in the cluster near its billing (that is hour) boundary. This policy was based on the fact that AWS billing was hourly and it always made sense to keep machines running until the full hour was up.
Understanding the QDS Cluster Lifecycle covers the current termination protocol in more detail.
Behavior with Aggressive Downscaling
After enabling the aggressive downscaling feature, the Idle Cluster Timeout can be configured in minutes. Its minimum configurable value is 5 minutes and the default value would still remain 2 hours (that is 120 minutes). Once the cluster is idle for the configured duration, QDS terminates the cluster (and will no longer wait for one of the nodes to reach its hourly boundary). The new policy provides cost reduction by exploiting AWS per-second billing for EC2 instances.
Note
Qubole periodically checks if the cluster is idle every 5 minutes . Due to this, the cluster termination (because of inactivity) can get delayed by a maximum of 5 minutes.
For example, consider the Idle Cluster Timeout is set to 5 minutes (default value). Here is a sequential procedure on how the cluster becomes eligible for auto termination:
When cluster is started, Qubole checks the cluster state at time, t=0 minute.
When
t= 1 minutequery/command execution is completed.As Qubole checks the cluster state every 5 minutes, when
t= 5 minutes, Qubole checks the cluster state but it does not consider the cluster for termination as it is only 4 minutes since the cluster has been idle.In the next time interval, that is t=10 minutes, Qubole checks the cluster state and marks it eligible for termination. In this case, the cluster is idle for 9 minutes. This is how a delay of 4 minutes happens in the cluster termination even though the configured idle cluster timeout is 5 minutes.
Understanding the Changes in the Cluster UI
As before, you can configure the Idle Cluster Timeout at the Account level and at the Cluster level. If the Timeout value is specified at Cluster level, then it overrides the Account level configured timeout. If no timeout value is specified at Cluster level, then the Account-level value is applicable.
Account Level: You can configure the Idle Cluster Timeout at account level for all clusters through the Account Settings controls in the Control Panel as shown here:
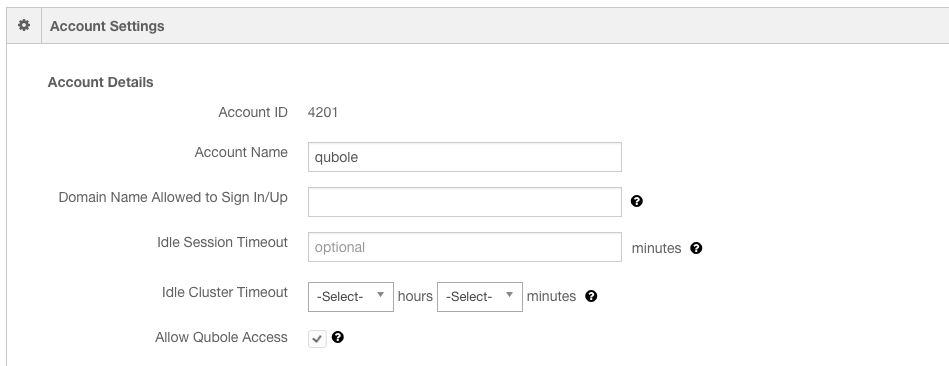
Cluster Level: Configure the Idle Cluster Timeout at an individual cluster-level by editing the cluster from the Clusters page. The Cluster Edit UI for the cluster timeout is as shown here.
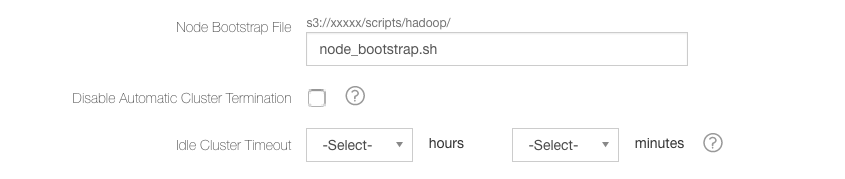
Note
If the Idle Cluster Timeout value is lower than the Cool Down Period, the former takes precedence over the latter.
Important Note for Notebook/Spark Users
As described in the cluster lifecycle documentation, the notebook’s Spark interpreters have a
separate Idle timeout (spark.qubole.idle.timeout) with a default value of 60 minutes. Since running Spark interpreters
block cluster termination, which means that if you are a Spark/Notebook user, you may also have to change the idle
timeout setting in the interpreters for faster cluster termination to be effective. Qubole is investigating schemes
whereby Spark interpreter configurations can be controlled centrally and are in harmony with the Idle Cluster Timeout
setting.
Understanding Changes in Downscaling for Hadoop 2/Spark
Hive/Map-Reduce/Pig/Spark workloads run on clusters managed by YARN. This section covers the downscaling changes applicable for any YARN-based cluster (and it does not apply to Hadoop 1 and Presto clusters).
As described in the cluster downscaling protocol is described in Autoscaling in Qubole Clusters, currently QDS can remove nodes from a YARN cluster only when the node is approaching its hourly boundary (for example, an hourly boundary in the case of AWS). With the aggressive downscaling changes, the concept of hourly boundary is no longer valid. Nodes can be terminated immediately after a node becomes idle (and satisfies any other downscaling requirements). This results in cost savings for customers as early termination of nodes in conjunction with per-second AWS billing results in lower cost.
These sub-sections elaborately describe how aggressive downscaling works with Hadoop2/Spark clusters:
Cool Down Period
Rapid downscaling can result, counter-intuitively in inefficiency and bad user-experience as mentioned here:
Nodes could waste most of the time in booting up if they are terminated too quickly.
Users submitting workloads into a cluster may find poor response time as clusters must always upscale to serve workloads (and downscale immediately thereafter).
To prevent such thrashing, QDS has introduced a new concept called Node Cool Down and an associated configurable time period. After a node becomes idle and eligible for termination, QDS waits for the Cool Down Period before terminating a node. All nodes in the cool-down time period are moved to the Graceful Shutdown state (where new tasks are not scheduled against the node and it is also decommissioned from HDFS). This allows QDS to quickly recommission the node if required (or remove it after the cool-down time period has expired).
Configure the Cool Down Period for a cluster through the UI by performing these steps:
Navigate to the Clusters page. Edit the cluster configuration for an existing cluster (or add it while creating a new cluster).
In the Composition tab of the cluster configuration, there is a Cool Down Period option which has two separate drop-down lists for On-Demand and Spot nodes. Here is an example of the Composition tab.
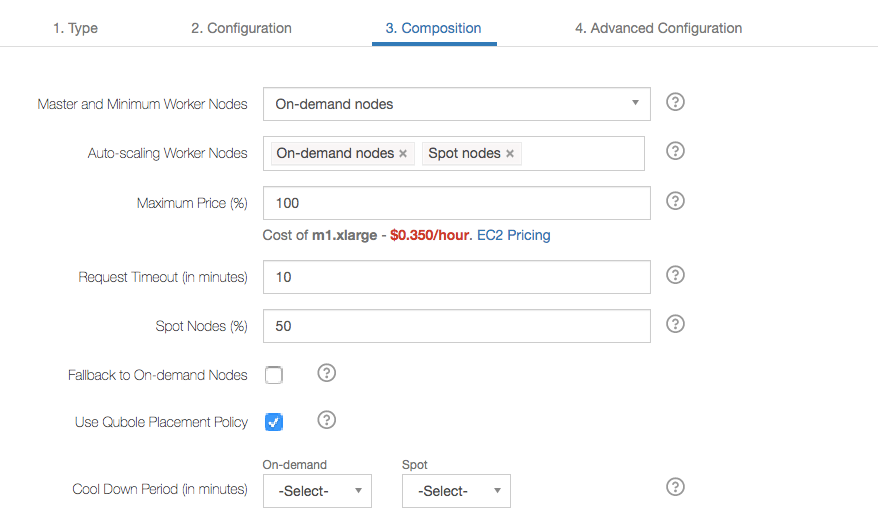
Set the Cool Down Period for On-Demand and Spot nodes, or let it default. The default is:
10 minutes for On-Demand nodes
15 minutes for Spot Nodes
Note
You should not set the Cool Down Period to a value lower than 300 seconds or 5 minutes. A lower value may be greater than the time it takes to decommission the node.
Note
The node_configuration parameters table lists:
The
node_base_cooldown_periodparameter for the On-Demand nodes that you can use to configure the Cool Down Period through the cluster API call.The
node_spot_cooldown_periodparameter for Spot nodes that you can use to configure the Cool Down Period through the cluster API call.
Spot versus On-Demand Nodes
Spot instances may take much longer time to provision than On-Demand instances. In addition, they are also usually significantly cheaper. To account for these differences, Spot instances have a longer cool down duration compared to On-Demand nodes.
The default Cool Down Period for Spot nodes is set to 900 seconds (that is 15 minutes) as opposed to 600 seconds (that is 10 minutes) for On-Demand nodes.
Recommissioning
As the Spot instances are retained for a longer period of time, the overall Spot node percentage (%) in the cluster might go up. To address this issue, Recommissioning ensures that the configured cluster composition (Spot versus On-Demand %) is honored and the ratio of active Spot instances in YARN does not go beyond the configured composition. For instance, if the Spot instance % is already at the configured maximum and a new node is required, rather than recommissioning any available spot node in a cool-down state, a new On-Demand node is provisioned.
Understanding Faster Cluster Downscaling for Presto
On QDS Presto, configure Cool Down Period on Presto clusters to not wait for a node to reach the hourly boundary before downscaling it. It is a cluster level cool down period, which starts after the cluster is found being underutilized. The downscaling does not start unless throughout this period, it is seen that the cluster is under utilized making it eligible for downscaling.
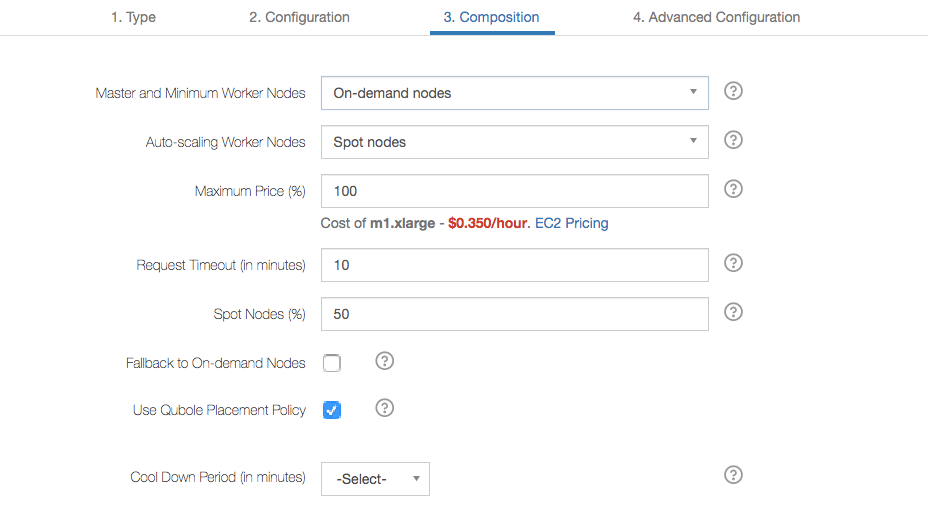
The default value of the Cool Down Period for Presto cluster nodes is 5 minutes. If you do not specify any value in the UI, the default value is applied.
Note
The node_configuration parameters table lists the node_base_cooldown_period parameter that you can
use to configure the Cool Down Period through the cluster API call.
The Cool Down period that ascm.downscaling.staggered uses is configurable when the aggressive downscaling
is enabled but its behavior remains the same as described in Controlling the Nodes’ Downscaling Velocity.