Autoscaling in Presto Clusters
Here’s how autoscaling works on a Presto cluster:
Note
Presto is supported on AWS, Azure, and GCP Cloud platforms; see QDS Components: Supported Versions and Cloud Platforms.
The Presto Server (running on the coordinator node) keeps track of the launch time of each node.
At regular intervals (10 seconds by default) the Presto Server takes a snapshot of the state of running queries, compares it with the previous snapshot, and estimates the time required to finish the queries. If this time exceeds a threshold value (set to one minute by default and configurable through
ascm.bds.target-latency), the Presto Server adds more nodes to the cluster. For more information onascm.bds.target-latencyand other autoscaling properties, see Presto Configuration Properties.If QDS determines that the cluster is running more nodes than it needs to complete the running queries within the threshold value, it begins to decommission the excess nodes.
Note
Because all processing in Presto is in-memory and no intermediate data is written to HDFS, the HDFS-related decommissioning tasks are not needed in a Presto cluster.
After new nodes are added, you may notice that they sometimes are not being used by the queries already in progress. This is
because new nodes are used by queries in progress only for certain operations such as TableScans and Partial Aggregations.
You can run EXPLAIN (TYPE DISTRIBUTED) (see EXPLAIN)
to see which of a running query’s operations can use the new nodes: look for operations that are part
of Fragments and appear as [SOURCE].
If no query in progress requires any of these operations, the new nodes remain unused initially. But all new queries started after the nodes are added can make use of the new nodes (irrespective of the types of operation in those queries).
QDS skips requesting instances of the families for which spot losses were seen at the cluster level within a specified time window (default duration is last 15 minutes). If spot losses were seen for all configured instance families, QDS tries to provision instances synchronously, and finally falls back to On-Demand if configured in case of unavailability of spot nodes. Qubole recommends configuring instances of multiple families. Create a ticket with Qubole Support to enable this configuration.
Whenever a spot loss notification is received in a Presto cluster, Qubole’s autoscaling immediately starts adding replacement nodes to the cluster without waiting for the spot node to be interrupted by Cloud Provider. This ensures that disruption to workloads due to the number of workers in the cluster reducing is minimal. However, this may result in the cluster’s size going above its configured maximum size for the brief interval when the about-to-be-lost spot nodes are still up and their replacement nodes have started arriving in the cluster.
Note
Presto clusters support configuring buffer capacity on clusters that is used when a query is submitted to the cluster. For more information, see Configuring Buffer Capacity in Presto Clusters.
Configuring Spot Block Nodes as Autoscaling Nodes
Previously, Qubole supported Spot block nodes only for fixed duration clusters. Now, you can configure AWS Spot Block nodes as auto-scaling nodes for long running clusters as well. This is a beta feature and to use this feature, create a ticket with Qubole Support.
Spot block nodes are 30% to 50% cheaper compared to On-Demand nodes and are more reliable than Spot nodes as they are acquired for a predefined duration (1 to 6 hours). Qubole minimizes query failures by intelligently replacing spot block nodes with new nodes before their expiry. Replacement of Spot Block nodes can be configured depending based on the expected runtime of queries that are executed on a cluster.
These are the Presto configuration properties that you can override on a Presto cluster:
ascm.node-expiry-period: This defines the time before the Spot block duration end of a node when Qubole starts the graceful shutdown of a node. You must configure this value based on the maximum query execution time that queries must be allowed to run without encountering a node loss. The default value is 15 minutes.Example: For a node with spot block duration of 4 hours (
4h), ifascm.node-expiry-period=10m, then 10 minutes before the node’s spot block duration completes, Qubole stops scheduling any additional tasks on this node and shuts it down as soon as its existing tasks complete.ascm.node-recycle-period: This defines the time beforeascm.node-expiry-periodwhen Qubole starts proactively adding spot block nodes to replace the ones that are about to expire. A proactive rotation is required to maintain cluster at its optimal size without being affected by the expiry of spot block nodes. Qubole spreads out replacement of nodes over theascm.node-recycle-periodto avoid unnecessary upscaling of the cluster by a large number of nodes. The default value is 15 minutes.
Configuring the Required Number of Worker Nodes
Note
This capability is supported only in Presto 0.193 and later versions.
You can configure query-manager.required-workers as a cluster override to set the number of worker nodes that
must be running before a query can be scheduled to run. This allows you to reduce
the minimum size of Presto clusters to one without causing queries to fail because of limited resources.
(While nodes are being requested from the Cloud provider and added to the
cluster, queries are queued on Presto’s coordinator node. These queries are shown as Waiting for resources
in the Presto web UI.)
QDS waits for a maximum time of query-manager.required-workers-max-wait (default 5 minutes)
for the configured number of nodes to be provisioned. Queries which do not require multiple worker nodes
(for example, queries on JMX, system, and information schema connectors, or queries such as SELECT 1 and SHOW CATALOGS)
are executed immediately. The cluster downscales to the minimum configured size when
there are no active queries.
Qubole allows overriding the cluster-level properties, query-manager.required-workers-max-wait and
query-manager.required-workers at query-level through the corresponding session properties,
required_workers_max_wait and required_workers.
Let us consider this example.
SET SESSION required_workers=5;
SET SESSION required_workers_max_wait='3m';
select * from foo;
This ensures that the query is not scheduled until at least 5 nodes are in the cluster or until 3 minutes have elapsed.
The number of worker nodes that autoscaling brings up is capped by the lower value between the cluster’s maximum size or
resource groups’ maxNodeLimit (if it has been configured).
This feature is useful for upscaling the cluster to handle scheduled ETLs and reporting jobs whose resource requirements are well known.
Note
These are autoscaling nodes and adhere to the existing cluster configuration for Spot nodes.
Controlling the Nodes’ Downscaling Velocity
The autoscaling service for Presto triggers an action of removing the ascm.downscaling.group-size (with its default=5)
nodes during each configured ascm.decision.interval (with its default=10s) if it calculates the optimal size of the
cluster to be less than the current cluster size continuously for the configured Cool down period. This results in a
downscaling profile where no nodes are removed during the Cool down period and nodes are removed very aggressively until
the cluster reaches its optimal size.
This figure illustrates the downscaling profile of cluster nodes.
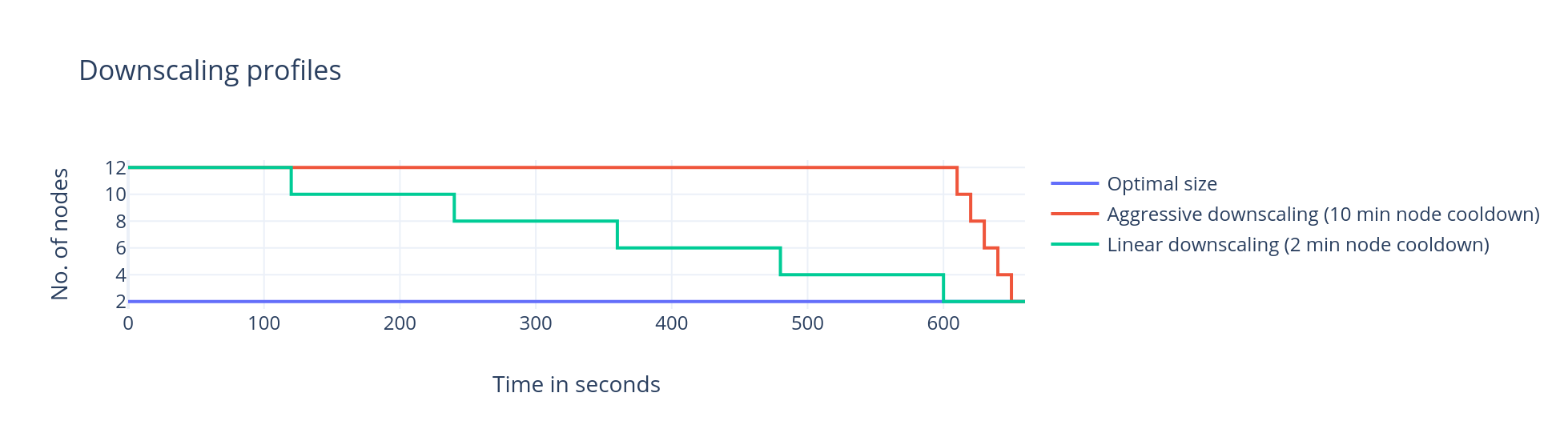
To control the nodes’ downscaling velocity, Qubole provides a Presto cluster configuration override, ascm.downscaling.staggered=true.
When you override it on the cluster, every time a downscaling action is triggered, the Cool down period is reset, which has
a default value of 5 minutes. The next downscaling action is not triggered by the autoscaling service until it calculates
the optimal size of the cluster to be less than the current cluster size continuously for the configured Cool down period.
This results in a more gradual downscaling profile where ascm.downscaling.group-size nodes are removed in each
Cool down period until the cluster reaches its optimal size.
For better understanding, let us consider these two examples.
Example 1: Consider a cluster without ascm.downscaling.staggered enabled.
The configured Cool down period is 10m. The current cluster size is 12 and optimal size is 2 with ascm.downscaling.group-size=2.
In this case, for 10 minutes no nodes are removed– that is while the Cool down period lasts. After that, 2 nodes are removed every 10 seconds until the cluster size is 2.
The total time taken to get to optimal size is (cool down period + ((current - optimal)/group_size) * 10s) = 10 minutes and 50 seconds.
Example 2: Consider a cluster with ascm.downscaling.staggered enabled.
The configured Cool down period is 2m. The current cluster size is 12 and optimal size is 2 with ascm.downscaling.group-size=2.
In this case, 2 nodes are removed every 2 minutes until the cluster size is 2.
The total time taken to get to optimal size is ((current - optimal)/group_size) * cool down period) = 10 minutes.
In addition, Presto also supports resource groups based dynamic cluster sizing at the cluster and account levels as described in Resource Groups based Dynamic Cluster Sizing in Presto.
Decommissioning a Worker Node
Qubole allows you to gracefully decommission a worker node during autoscaling through the cluster’s coordinator node. If you find a problematic worker node, then you can manually remove it using the cluster API as described in Remove a Node from a Cluster.