Configuring a Spark Cluster
By default, each account has a Spark cluster; this cluster is used automatically for Spark jobs and applications. You can add a new Spark cluster and edit the configuration of the default Spark cluster on the Clusters page. QDS clusters are configured with reasonable defaults.
Adding a New Spark Cluster
Navigate to the Clusters page.
Click the New button near the top left of the page.
On the Create New Cluster page, choose Spark and click Next.
Specify a label for a new cluster in the Cluster Labels field.
Select the version from the Spark Version drop-down list.
In the drop-down list, Spark 3.x-latest means the latest open-source maintenance version of 3.x. When a new maintenance version is released, Qubole Spark versions are automatically upgraded to that version. So if 3.3-latest currently points to old versions, then, when 3.3.2 is released, the QDS Spark clusters running 3.3-latest will automatically start using 3.3.2 on a cluster restart. See QDS Components: Supported Versions and Cloud Platforms for more information about Spark versions in QDS.
Note
Spark 3.3.2 is already released and available in QDS.
Select legacy or user as the Notebook Interpreter Mode from the drop-down list.
For information on Notebook Interpreter Mode on a Spark cluster, see Using the User Interpreter Mode for Spark Notebooks.
Select the coordinator node type and worker node type from the appropriate dropdown list.
Note
Qubole provides an option to disallow creation of Spark clusters with low memory instances (memory < 8 GB) for Spark clusters. This option is not available for all users by default. Create a ticket with Qubole Support to enable this option. With this option, the existing cluster that uses a low memory instance fails.
Cluster autoscaling is enabled by default on Qubole Spark clusters. The default value of Maximum Worker Nodes is increased from 2 to 10.
Enter other configuration details in the Composition and Advanced Configuration tabs and click Create.
The newly created cluster is displayed in the Clusters page.
Editing the Cluster Configuration
Navigate to the Clusters page.
Click the Edit button next to the cluster.
Edit the required configuration.
If you changed the Spark version, then restart the cluster for the changes to take effect.
Click Update to save the configuration.
Note
After you modify any cluster configuration, you must restart the cluster for the changes to take effect.
Note
There is a known issue for Spark 2.2.0 in Qubole Spark: Avro write fails with
org.apache.spark.SparkException: Task failed while writing rows. This is a known issue in the
open-source code. As a workaround, append the following to your node bootstrap script:
rm -rf /usr/lib/spark/assembly/target/scala-2.11/jars/spark-avro_2.11-3.2.0.jar
/usr/lib/hadoop2/bin/hadoop fs -get s3://paid-qubole/spark/jars/spark-avro/spark-avro_2.11
See Managing Clusters for instructions on changing other cluster settings.
Handling Spot Node Loss in Spark Clusters (AWS)
Spark on Qubole proactively identifies the nodes that undergo Spot loss, and stops scheduling tasks on the corresponding executors.
This feature is supported on Spark versions 2.1.0, 2.1.1, 2.2-latest, and later versions, and is controlled using the spark configuration spark.qubole.spotloss.handle.
By default, the Spark configuration spark.qubole.spotloss.handle is set to true.
Perform the following steps to disable this feature:
Navigate to the Edit Cluster Settings > Advanced Configuration page.
Set the Spark configuration as:
spark.qubole.spotloss.handle=falsein the Override Spark Configuration field of the SPARK SETTINGS section.Restart the cluster for the changes to take effect.
For more information about spot node loss handling in Qubole, see Exploiting AWS Spot Instance Termination Notifications in Qubole.
Viewing a Package Management Environment on the Spark Cluster UI
When you create a new Spark cluster, by default a package environment gets created and is attached to the cluster. This feature is not enabled by default. Create a ticket with Qubole Support to enable this feature on the QDS account.
You can attach a package management environment to an existing Spark cluster. For more information, see Using the Default Package Management UI.
Once an environment is attached to the cluster, you can see the ENVIRONMENT SETTINGS in the Spark cluster’s Advanced Configuration. Here is an environment attached to the Spark cluster.
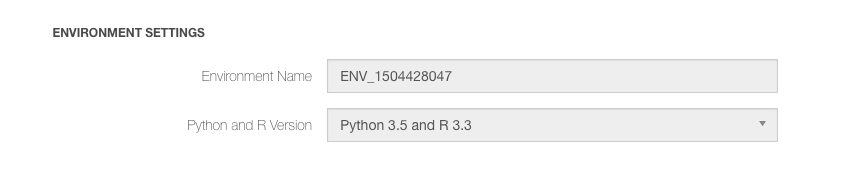
The default environment gets a list of pre-installed Python and R packages. To see the environment list, navigate to the Control Panel > Environments.
Configuring Heterogeneous Nodes in Spark Clusters
An Overview of Heterogeneous Nodes in Clusters explains how to configure heterogeneous nodes in Hadoop 2 and Spark clusters.
Overriding the Spark Default Configuration
Qubole provides a default configuration based on the Worker Node Type. The settings are used by Spark programs running in the cluster whether they are run from the UI, an API, or an SDK.
The figure belows shows the default configuration.
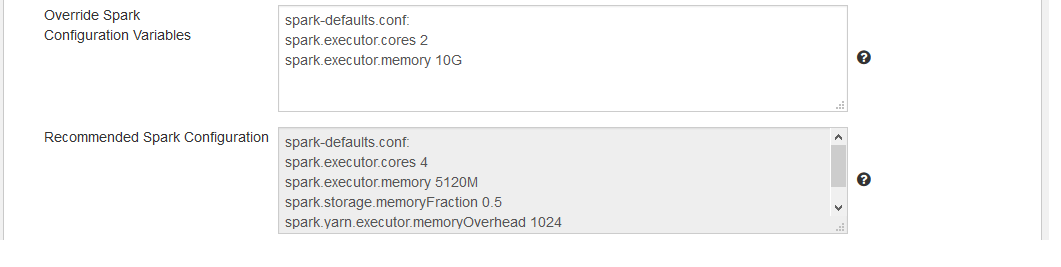
Note: Use the tooltip to get help on a field or check box.

To change or override the default configuration, provide the configuration values in the Override Spark Configuration Variables text box. Enter the configuration variables as follows:
In the first line, enter spark-defaults.conf:. Enter the <key> <value> pair in subsequent lines.
Provide only one key-value pair per line; for example:
spark-defaults.conf:
spark.executor.cores 2
spark.executor.memory 10G
To apply the new settings, restart the cluster.
To handle different types of workloads (for example, memory-intensive versus compute-intensive) you can add clusters and configure each appropriately.
Setting Time-To-Live in the JVMs for DNS Lookups on a Running Cluster
Qubole now supports configuring Time-To-Live (TTL) JVMs for DNS Lookups in a running cluster (except Airflow and Presto).
This feature is not enabled by default. Create a ticket with Qubole Support for
enabling this feature on the QDS account. The recommended value of TTL is 60 and its unit is seconds.