Configuring a HiveServer2 Cluster
QDS supports HiveServer2 on Hadoop clusters.
Enable HiveServer2 in the QDS UI, in the Hive Settings section under the Advanced Configuration tab of the Clusters page.
You can configure HS2 clusters to use private IP for communication between the coordinator node and worker nodes at cluster level
by passing hive.hs2.cluster.use.private.ip=true as an override in cluster’s Advanced Configuration >
HIVE SETTINGS > Override Hive Configuration. To enable it on the account, create a ticket with
Qubole Support to enable it on the QDS account.
Enabling HiveServer2
All queries run on a HiveServer2-enabled cluster use HiveServer2. If you want to enable HiveServer2 only for a specific query, without enabling it on a cluster, add this to the query:
set hive.use.hs2=true;
When HiveServer2 is enabled, all Hive queries are executed on the cluster coordinator node, including queries running DDL
statements such as ALTER TABLE RECOVER PARTITIONS.
Note
Once Qubole has enabled Hive Authorization in your account:
QDS sets
hive.security.authorization.enabledtotrue, and adds it to Hive’s Restricted List. This prevents users from bypassing Hive authorization when they run a query.If you want to change the setting of
hive.security.authorization.enabledat the cluster level, you can do so in the QDS UI: set it in the Override Hive Configuration field in the Hive Settings section under the Advanced Configuration tab of a Hadoop (Hive) cluster, then restart the cluster.To change the setting at the account level, create a Qubole support ticket.
Verifying that Hive Queries are using HiveServer2
To verify that queries are being directed to HiveServer2, look in the query logs for statements similar to the following:
2016-11-08 04:19:22,485 INFO hivecli.py:412 - getStandaloneCmd - Using HS2
Connecting to jdbc:hive2://<master-dns>:10003
Connected to: Apache Hive (version 2.1.0)
Driver: Hive JDBC (version 2.1.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Understanding Memory Allocation to HiveServer2
When HiveServer2 is enabled, QDS reserves memory for it when the cluster starts, allocating an approximate value of 25-30% (depending on the memory given to other daemons on the cluster) of the memory obtained from the YARN ResourceManager to HiveServer2. This has an impact on how many concurrent queries users can run on the cluster: QDS configures the concurrency limitation in the node bootstrap script, setting it to 500MB for one query.
HiveServer2 is deployed on the coordinator node, so you should configure a powerful instance type for it; the total RAM size must be at least 15 GB.
Create a ticket with Qubole Support for help if you are not sure about the optimal configuration.
Note
You can enable HiveServer2, with additional settings, through a Hadoop API call as described in engine_config for Enabling HiveServer2 on a Hadoop 2 (Hive) Cluster.
Understanding Hive Metadata Caching
Hive Metadata Caching, supported on Hadoop clusters, reduces the split computation time for ORC files currently by caching the meta data required in split computation on Redis running on the coordinator node. It is very useful when the data contains many ORC files. Qubole plans to extend this feature support to Parquet files in the near future. Configure it in the QDS UI, in the Hive Settings section under the Advanced Configuration tab of the Clusters page:
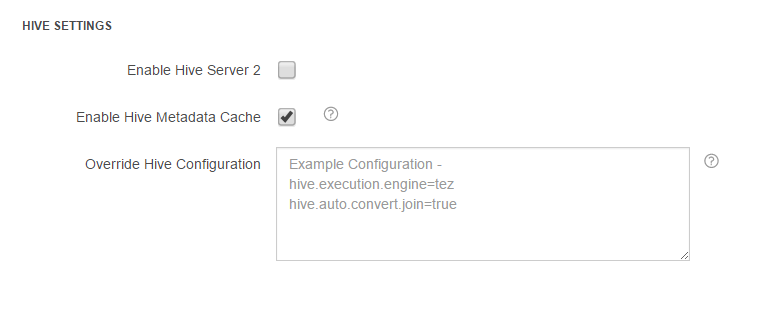
If you do not see the Enable Hive Metadata Cache option for a Hadoop cluster, create a ticket with Qubole Support to enable it for your QDS account.
Note
As a prerequisite, enable Hive on coordinator or Hive on HiveServer2 before enabling Hive Metadata Cache.
Once metadata caching is enabled on a QDS account, it is enabled by default only on new Hadoop (Hive) clusters; it remains disabled on existing clusters.
Enabling metadata caching installs a Redis server on the cluster. You can turn caching on and off at the
query level by setting hive.qubole.metadata.cache to true or false. You can also add this setting
in the Hive bootstrap script.
You can also enable Hive Metadata caching through a REST API call as described in engine_config for Enabling HiveServer2 on a Hadoop 2 (Hive) Cluster.
Setting Time-To-Live in the JVMs for DNS Lookups on a Running Cluster
Qubole supports configuring Time-To-Live (TTL) JVMs for DNS Lookups in a running cluster (except Airflow and Presto).
This feature is not enabled by default; create a ticket with Qubole Support to
enable it. The recommended value of TTL is 60 and its unit is seconds.