Configuring Multi-instance HiveServer2
Qubole provides an additional option to run HiveServer2 (HS2) with a Hadoop (Hive) cluster, which is called multi-instance HiveServer2. It is recommended to configure and use this option HS2 when you expect high concurrency of workloads or peak traffic volume is much larger than the average workloads.
When multi-instance HS2 option is selected, Qubole manages HS2 JVM life cycles automatically and it is transparent to the end users running workloads on the Hadoop (Hive) Cluster. Multi-instance HS2 is only supported in Hive versions 2.1.1, 2.3, and 3.1.1 (beta).
This enhancement is available for beta access and it is not available by default. Create a ticket with Qubole Support to enable it on the QDS account.
Qubole has added support for load-aware autoscaling and agent-based adaptive load balancing in HS2 clusters. Create a ticket with Qubole Support to enable it on the QDS account.
Note
Datadog monitoring is supported for multi-instance HS2 along with HS2. The configuration is the same that is configured with the associated Hadoop (Hive) cluster. HiveServer2 metrics are described in Understanding the HiveServer2 Metrics.
These sections help you understand the lifecycle and configuration of multi-instance HS2:
Configuring Multi-instance HS2
You can configure a multi-instance HS2 through the UI and the REST API as well.
This topic describes how to configure a multi-instance HS2 through the Clusters UI. For details on configuring multi-instance HS2 through REST API, see Choosing Multi-instance as an option for running HiveServer2 on Hadoop (Hive) Clusters.
Perform these steps to configure multi-instance HS2:
Navigate to the Qubole UI > Clusters.
Go to the Hadoop (Hive) cluster on which you want to configure a multi-instance HS2.
Click the Advanced Configuration tab. Under HIVE SETTINGS, pull the drop-down list. It displays two other options besides the Disabled (default) option as illustrated here.
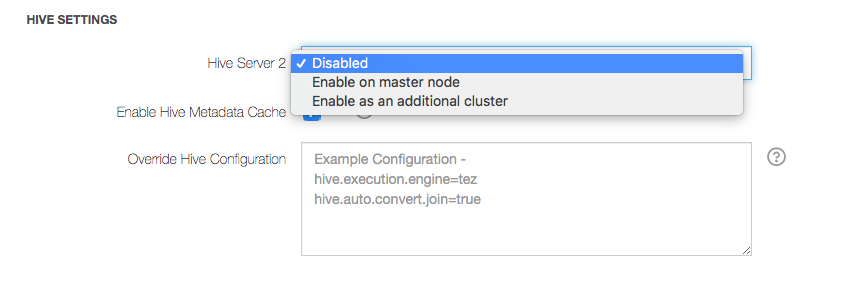
Choose Enable as an additional cluster and you can see the Edit button as illustrated here.
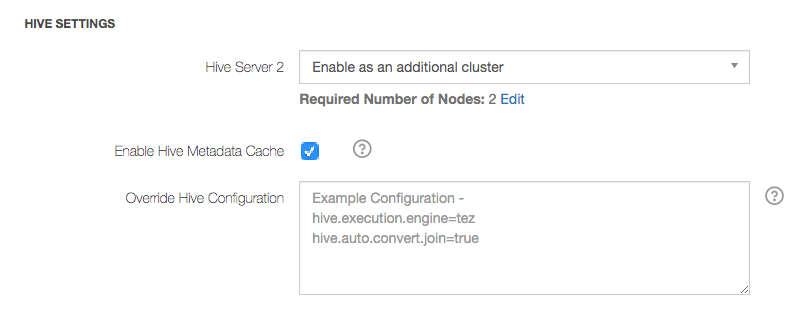
Click Edit to see the HS2 Settings tab for multi-instance HS2 as illustrated here.
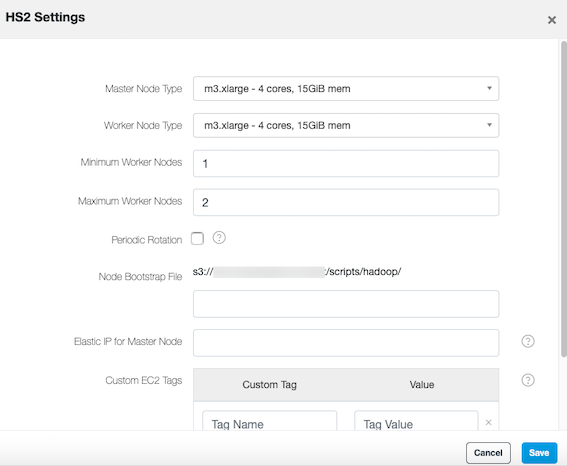
Select the Coordinator Node Type if you want a different coordinator node type for multi-instance HS2 than the default node type.
Select the Worker Node Type if you want a different worker node type for multi-instance HS2 than the default node type.
The default Minimum Number of Nodes is set to 1. It decides the minimum number of worker nodes that must be present in the multi-instance HS2 cluster.
The default Maximum Number of Nodes is set to 2. It decides the maximum number of worker nodes that the cluster can have. Nodes get added in a multi-instance HS2 cluster by autoscaling and periodic rotation. To know more, see Periodic Rotation.
Enable Periodic Rotation if you wish to periodically rotate worker nodes to avoid any possible performance degradation. Ensure that the Maximum Number of Nodes is greater than Minimum Number of Nodes by at least 1, for the periodic rotation to work. To know more, see Periodic Rotation.
You can specify a different node bootstrap file location if you want to change its default location inherited from the associated Hadoop (Hive) cluster.
Enter the Elastic IP of Coordinator Node for multi-instance HS2. When you want to directly (through external Business Intelligence (BI) tools) run queries on multi-instance HS2, you can attach an Elastic IP (EIP) to the multi-instance HS2 and configure the tools to connect to the EIP of the multi-instance HS2’s coordinator node. You must add EIP to the HS2 coordinator node because HS2 queries run on the multi-instance HS2 instead of the associated Hadoop (Hive) cluster.
Add custom EC2 tags and the corresponding values. Ensure that you do not add reserved keywords as EC2 tags as described in Advanced configuration: Modifying EC2 Settings (AWS).
Click Save to save HS2 Settings.
Lifecycle of Multi-instance HS2
The lifecycle of multi-instance HS2 is intrinsically associated with the Hadoop (Hive) cluster. The multi-instance HS2 starts and stops with the associated Hadoop (Hive) cluster.
Ideally, you must not terminate the multi-instance HS2 without stopping the associated Hadoop (Hive) cluster. Qubole provides the option to only terminate the multi-instance HS2 as a safeguard against any possible bugs and runaway clusters.
Periodic Rotation
As HiveServer2 is a long-running JVM, its performance may get impacted due to issues such as heap memory leaks, native memory leaks, and Garbage Collection issues. It can happen over time and eventually can bring the system to a grinding halt. To avoid such performance degradation, Qubole allows you to refresh nodes periodically.
Nodes get added in a multi-instance HS2 for the following reasons:
Autoscaling: Based on the free query slots available, workload-aware autoscaling can add or remove worker nodes from the multi-instance HS2 by ensuring that the number of worker nodes are added between the configured minimum and maximum number of nodes.
Periodic Rotation: When you enable periodic rotation, Qubole periodically checks if the cluster has long running nodes that need a replacement. After detecting such nodes, it adds additional nodes to the cluster. After the newly added nodes start running, Qubole gracefully shuts down older nodes. As Qubole adds new worker nodes before terminating the older nodes, the maximum number of nodes configured for the cluster must be greater than minimum number of nodes, by at least 1. The difference would decide on how many nodes get replaced through the periodic rotation at a given time.