Configuring a Presto Cluster
A single Qubole account can run multiple clusters. By default, Qubole provides a Presto cluster, along with Hadoop and Spark clusters, for each account.
Note
Qubole allows you to push the spot percentage on a running Presto cluster. How to Push Configuration Changes to a Cluster describes the steps.
The following topics explain Presto custom configuration and the presto catalog properties:
Understanding the Presto Engine Configuration that describes:
Note
QDS provides the Presto Ruby client for better overall performance, processing DDL queries much faster and quickly reporting errors that a Presto cluster generates. For more information, see this blog.
To view or edit a Presto cluster’s configuration, navigate to the Clusters page and select the cluster with the label presto.
Click the edit icon in the Action column against a Presto cluster to edit the configuration.
Note
Presto queries are memory-intensive. Choose instance types with ample memory for both the coordinator and worker nodes.
You can select the Presto Version on the cluster configuration page. These are the supported versions:
0.193 is the deprecated version. While there are no restrictions on usage or creation of Presto-0.193 clusters, Qubole strongly recommends users to upgrade to 0.208 or later versions as a lot of new features are not ported back to deprecated versions.
0.208 is the default and stable version.
317 is the latest stable version.
See QDS Components: Supported Versions and Cloud Platforms for the latest version information.
Note
Qubole can automatically terminate a Presto cluster with an invalid configuration. This capability is available for Beta access; Create a ticket with Qubole Support to enable it for your account.
Check the logs in /usr/lib/presto/logs/server.log if there is a cluster failure or configuration error. See
Presto FAQs for more information about Presto logs.
The following figure shows Hadoop and Presto configuration override for a Presto cluster.
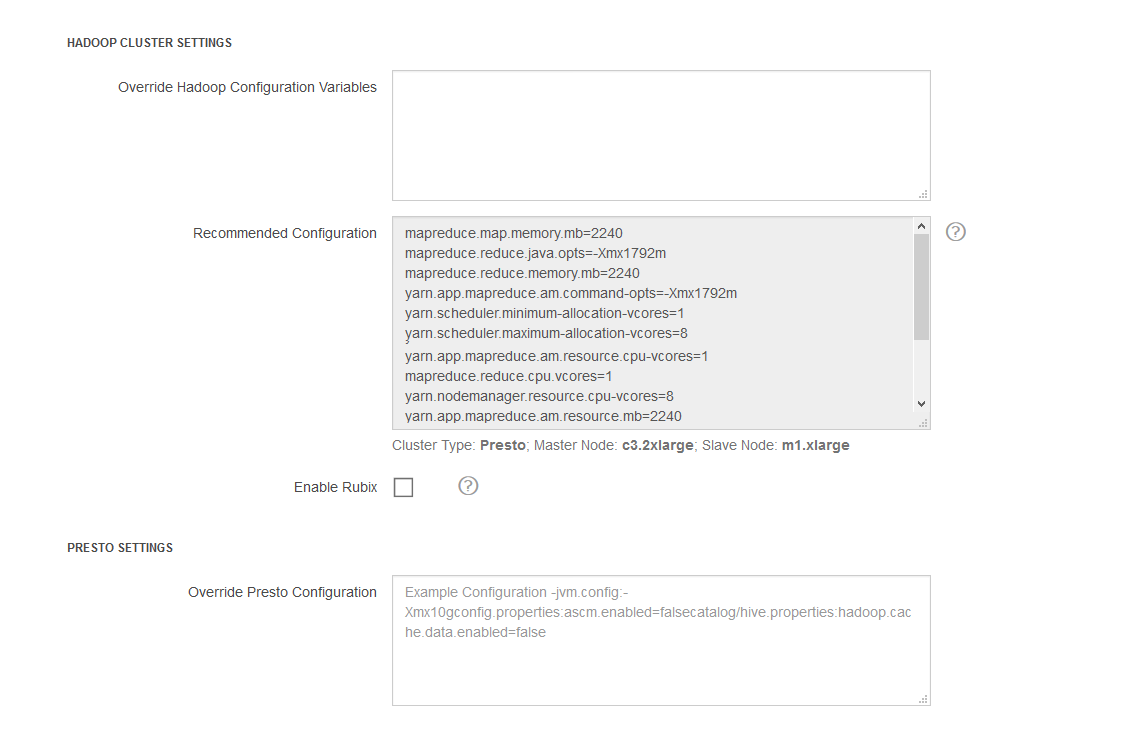
On AWS, Azure, or GCP, select Enable Rubix to enable RubiX. See Configuring RubiX in Presto and Spark Clusters for more information.
See Managing Clusters for more information on cluster configuration options that are common to all cluster types.
About Presto System Monitoring
Understanding the Presto Metrics for Monitoring describes the list of metrics that can be seen on the Datadog monitoring service. It also describes the abnormalities and actions that you can perform to handle abnormalities.
Avoiding Stale Caches
The cache parameters are useful to tweak if you expect data to change rapidly.
Fo example, if a Hive table adds a new partition, it may take Presto 20 minutes to discover it. If you plan on changing existing files in the Cloud, you may want to make fileinfo expiration more aggressive. If you expect new files to land in a partition rapidly, you may want to reduce or disable the dirinfo cache.