Understanding the Integration with Talend 7.1
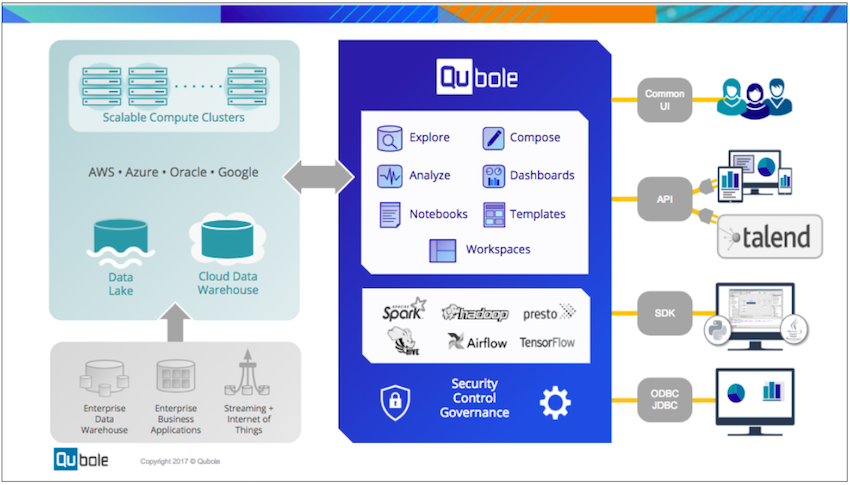
Understanding the Architecture
You can use Talend Studio to integrate data from various sources into the cloud data lake and build the data quality workflows to clean, mask, and transform data as per the business requirements. Then execute those jobs in Qubole leveraging Big Data engines such as Spark or Hive.
To execute serverless jobs in Talend, you have to specify the Qubole API token, Endpoint, and Cluster label (Hadoop2 or Spark) in the Talend Studio. Talend Studio sends the job to QDS, using the API Token to authenticate the user. QDS then executes the job automatically by starting the cluster specified as the Cluster label in Talend Studio.
During the job execution, Qubole automatically scales the cluster size up and down transparently and without any customer intervention, according to the data preparation job. If the Qubole cluster is configured to use the AWS Spot instances, Qubole automatically determines the bid, acquires, and rebalances the clusters to achieve an optimal price-performance combination.
Talend is responsible for job management while Qubole is responsible for the end-to-end job execution and monitoring as well as tracking history, and logging. Talend communicates with Qubole through the Qubole API.
Overview
The entire integration process has four steps. First, you need to create a QDS account if you don’t have already one. Second, you need to configure QDS to ensure interaction with the Talend Studio. Third, you have to install the Talend Studio and configure it to interact with Qubole. Finally, test your Spark or Hive configuration by using a simple Talend job (e.g. map and join columns from different random row generators).
