Snowflake (AWS)
The Qubole-Snowflake integration provides a new functionality that enables users to use Qubole Spark to run advanced data transformations and machine learning on Snowflake data warehouses.
With the Qubole-Snowflake integration, users can use the Qubole Data Service (QDS) UI, API, and Notebooks to read and write data to the Snowflake data warehouse by using the Qubole Dataframe API for Apache Spark. This functionality also provides simplified Spark configuration of Snowflake data warehouses with centralized and secure credential management.
The following diagram is the graphical representation of the Qubole-Snowflake integration architecture.
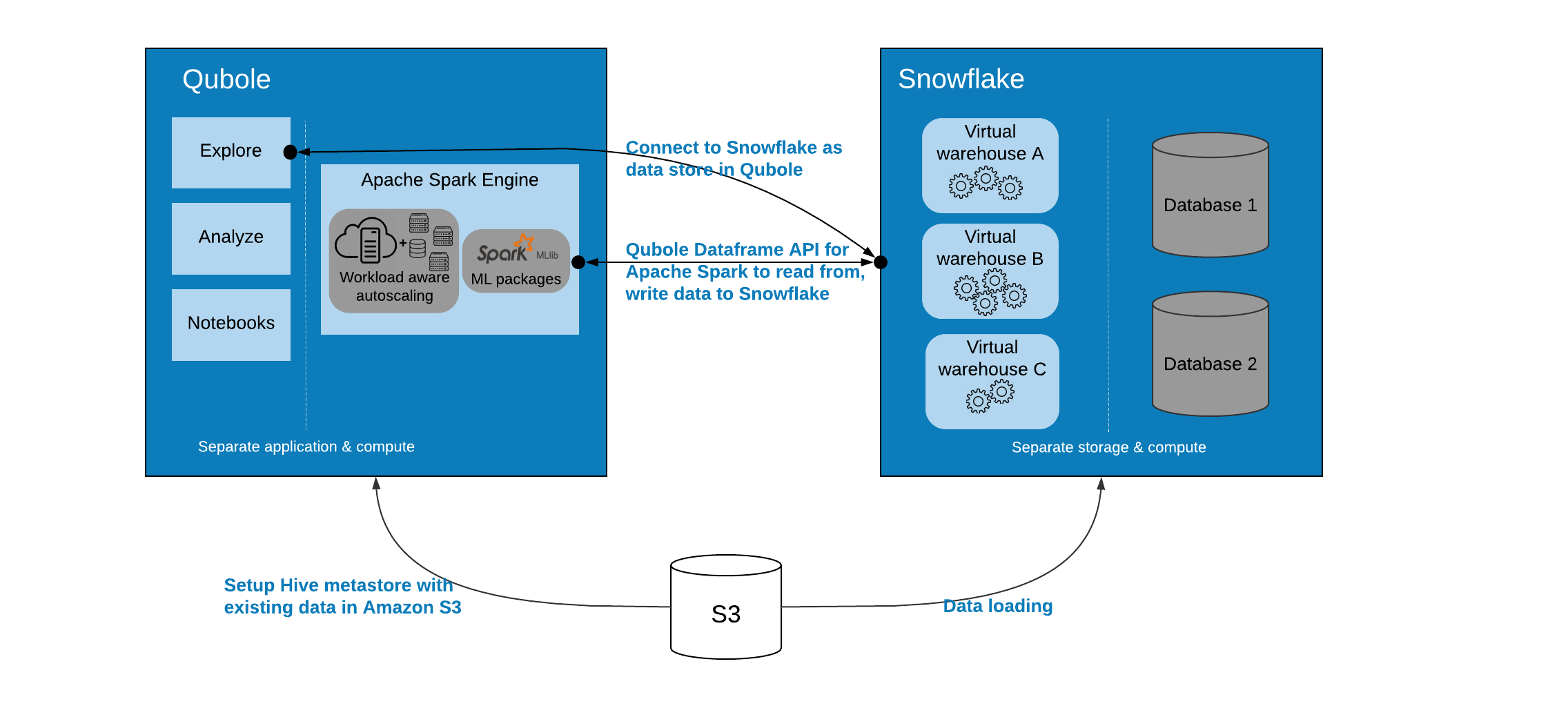
Users
Data engineers and data scientists are the key users to use QDS for accessing the data in the Snowflake data warehouse.
Data engineers can use Spark for advanced data transformations, such as, preparing and consolidating external data sources into Snowflake, or refining and transforming Snowflake data using Spark.
Data scientists can build, train, and execute ML and AI models in Spark using the data that already exists in the Snowflake data warehouse.
This guide provides information about the workflows, adding a Snowflake data warehouse to QDS, performing various read and write operations from and to the Snowflake data warehouse, and the related known issues and limitations:
- Understanding the Qubole-Snowflake Integration Workflows
- Understanding the parameters used for Snowflake
- Adding a Snowflake Data Warehouse as a Data Store
- Adding a Snowflake Data Warehouse as a Data Store with Bastion
- Performing Read and Write Operations on Snowflake Data Stores
- Snowflake Jars Packaged with Qubole Apache Spark Cluster
- Known Issues and Limitations