Configuring a Sample Spark job in Talend Studio
This configuration creates a sample Spark job to filter the rows from randomly generated data.
Open the Talend application.
Navigate to Repository > Job Designs at the left pane of the Talend window and create a Big Data Batch job.
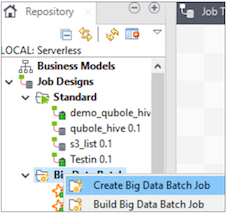
Name the job and click Finish. A standard job is created newly an opens up on the Designer window. It helps you to place components for creating a job.
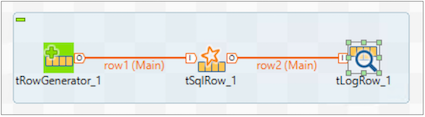
Use tRowGenerator component to generate data randomly.
Import tRowGenerator from the Palette into the designer window and click the component to set the schema and rule for random generation. Click the plus icon (+) to to add multiple columns, data types, functions, and limit of variables.
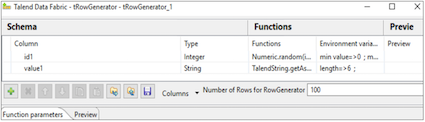
Click OK.
Add tSqlRow component to the job. It helps to process and filter the data.
Right-click the tRowGenerator, select Row > Main, and connect to tSqlRow.
Click tSqlRow to define the query and schema.
Click Sync columns to import the schema defined in tRowGenerator. Select SQL Spark Context and define the query for filtering.
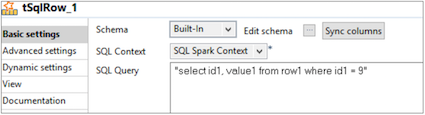
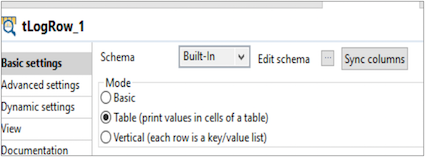
Print the filtered rows on the console using tLogRow.
Connect the logging component with tSqlRow as mentioned in step 7 and click Sync columns. Choose Mode of view as Table.
The Spark job is now displayed as shown below.
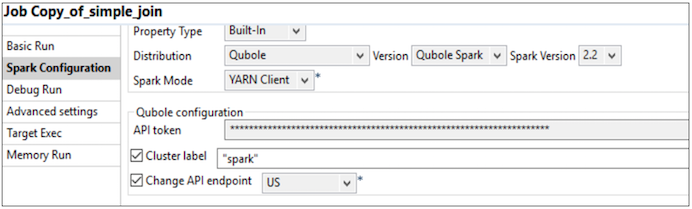
Navigate to the Run(Job_hive_sample_job) > Target Exec. Click Advanced settings and select Spark Configuration.
Specify the API token. If you want the execution on a configured cluster, enter the label name of the cluster in Cluster label field. API endpoint is https://api.qubole.com by default, however, you can specify the API endpoint based on your location. But you still have an option to check Change API endpoint and select the right endpoint based on your location.
Navigate to the Basic Run section and click Run to run the job. It triggers the Spark query in QDS.
You have successfully configured and run the sample Spark job.