Cluster Management
The new features and key enhancements are:
Separated Configuration of the Coordinator Node from the Minimum Number of Nodes
Gracefully Terminating Commands after Cluster Health Checks Fail
Other enhancements and bug fixes are listed in:
Account-level Node Bootstrap
ACM-6680: Qubole now supports an account-level node bootstrap, which is executed for all clusters of a specific account. Currently, it is only supported through the REST API. Cluster Restart Required
For more information, see the Edit a QDS Account and Edit a QDS Account using API version 2 pages.
Separated Configuration of the Coordinator Node from the Minimum Number of Nodes
ACM-5369: You can now configure coordinator and minimum number of nodes separately on the cluster configuration through the UI/API. This provides the flexibility to configure the coordinator node as On-Demand node type while rest of the nodes (minimum number of nodes and autoscaled nodes) as Spot Nodes (or Spot Block Nodes). However, Maximum Price (%) and Request Timeout common configuration applies to all three types of nodes (coordinator, minimum number of nodes and autoscaling). The stability of nodes has to be in the descending order from the coordinator, minimum number of nodes, and autoscaling nodes. Qubole has gradually rolled out this feature. Cluster Restart Required
The following table describes the supported combinations of coordinator, minimum number of nodes, and autoscaling nodes.
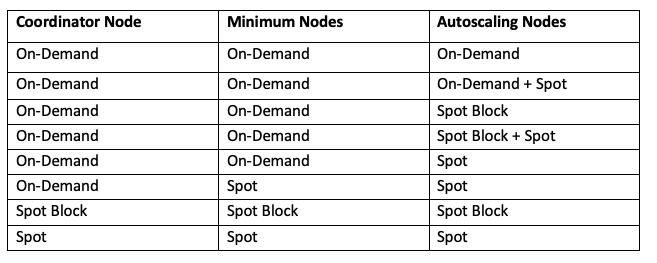
To know more, see configuration through UI and configuration through API.
Capacity-optimized as the Spot Allocation Strategy
ACM-6209: Qubole allows you to set capacity optimized as the spot allocation strategy for clusters on the
Advanced Configuration > Cluster Overrides of a specific cluster’s configuration UI. Configuring Cluster Overrides
describes the steps to set it. The default spot allocation strategy is lowest price (cost optimized). Gradual Rollout | Cluster Restart Required
Supported New Instances
ACM-6564: Qubole has added support for m5a, m5ad, r5a, and r5ad instance types. Cluster Restart Required
ACM-6585: Qubole has added support for c5.12xlarge and c5.24xlarge instance types. Cluster Restart Required
Gracefully Terminating Commands after Cluster Health Checks Fail
ACM-6659: QDS now gracefully terminates commands running on the cluster when the cluster is terminated either by the user or by Qubole after the cluster’s health check failures.
Handling Cluster Terminations
ACM-6255: Qubole has enhanced the way it handles cluster terminations, which includes clusters getting terminated due to unhealthy or idle clusters. Qubole also terminates a cluster when its start command times out. Gradual Rollout | Cluster Restart Required
ACM-4752: The cluster termination logs are now available in the Logs tab of the cluster instances UI page. Gradual Rollout
Enhanced Cluster Notifications
ACM-6288: These are the improvements in cluster notifications:
ACM-6451: Cluster notifications now have details on causes of the cluster health checks failure.
ACM-1211: Qubole sends a notification to the configured notification channel if the cluster start exceeds the timeout.
ACM-6309: Qubole has classified its cluster notifications into three different categories based on the severity level, which are:
ErrorInfoWarning
By default, Qubole sends notifications that fall under the
Errorseverity level. You can contact Qubole Support if you want notifications that haveInfoandWarningas the severity levels.
Enhancements
ACM-4105: Qubole allows you to add custom tags for Datadog metrics on a given cluster. It is available as a configurable option on Advanced Configuration > Cluster Overrides of a specific cluster’s configuration UI. Configuring Cluster Overrides describes the steps to add it. Gradual Rollout | Cluster Restart Required
ACM-4133: Support for heterogeneous Presto clusters is globally enabled. The instance type for heterogeneity in Presto clusters can be only one generation apart.
ACM-5019: Qubole lets you configure the coordinator instance type in a multi-instance HiveServer2 cluster. Cluster Restart Required
ACM-5560: Qubole has enhanced the error message in the cluster activity. It displays the user’s email who terminated the cluster manually.
ACM-6224: A HiveServer2 cluster configuration UI now allows configuration of periodic rotation and minimum and maximum nodes count. Cluster Restart Required
ACM-6239: Qubole sends cluster metrics,
cluster_max_sizeandcluster_min_sizeto the Datadog monitoring service.ACM-6297: A new HiveServer2 cluster supports using its associated Hadoop (Hive) cluster’s label as its own parameter.
ACM-6319: Qubole has optimized the API call for listing different cluster states.
ACM-6402: Qubole now supports configuring spot blocks in heterogeneous clusters. Gradual Rollout | Cluster Restart Required
ACM-6423: You can now aggregate metrics from multiple clusters at the account level through the account ID in Datadog.
ACM-6592: Qubole has added a Readme file for user-facing bootstrap library documentation.
ACM-6711: Qubole has enabled new heterogeneous configuration in the UI that appears as a suggestion while configuring the next worker node type. The UI suggests instances similar to the chosen worker node type but from different generations now. Earlier, the UI used to suggest the instance with the double weight of the same generation of the previously chosen worker node type.
Bug Fixes
ACM-3966: The Presto configuration overrides that are pushed to a running cluster has a P icon against it on the Presto cluster UI. Earlier, it was difficult to trace the configuration overrides that were pushed to a running Presto cluster.
ACM-5835: Qubole cleans up the dashboards and alerts associated with a specific cluster in the Datadog when that cluster is deleted. Earlier, dashboards and alerts of deleted clusters got accumulated in the Datadog account.
ACM-6035: A cluster activity tab UI now displays the cause for the cluster start failure if it occurs when the cluster fails to connect to the Hive metastore. Earlier, this cause for the cluster start failure was unknown.
ACM-6291: The issue where terminated clusters were incorrectly marked up due to a race condition between cluster termination and background healing jobs is fixed.
ACM-6551: The issue where Prometheus did not have any data after using a custom DNS name resolver is resolved.
ACM-6560: The issue where bringing up Prometheus resulted in unpopulated Grafana dashboards is resolved.
For a list of bug fixes between versions R58 and R59, see Changelog for api.qubole.com.