Create a Cluster
- POST /api/v2.2/clusters/
Use this API to create a cluster through the cluster API version 2.2.
Required Role
The following roles can make this API call:
A user who is part of the system-admin group.
A user invoking this API must be part of a group associated with a role that allows editing a cluster. See Managing Groups and Managing Roles for more information.
Parameters
Note
Parameters marked in bold below are mandatory. Others are optional and have default values.
Parameter |
Description |
|---|---|
A list of labels that identify the cluster. At least one label must be provided when creating a cluster. |
|
It contains the configurations of a cluster. |
|
It contains the configurations of the type of clusters |
|
It contains the cluster monitoring configuration. |
cloud_config
Parameter |
Description |
|---|---|
provider |
It defines the cloud provider. Set |
It defines the AWS account compute credentials for the cluster. |
|
location |
It is used to set the geographical AWS location. It comprises of the AWS region and AWS Availability Zone that are described in location. |
It defines the network configuration for the cluster. |
compute_config
Parameter |
Description |
|---|---|
compute_validated |
It denotes if the credentials are validated or not. |
use_account_compute_creds |
It is to use account compute credentials. By default, it is set to |
compute_access_key |
The EC2 Access Key. (Note: This field is not visible to non-admin users.) |
compute_secret_key |
The EC2 Secret Key. (Note: this field is not visible to non-admin users.) |
location
Parameter |
Description |
|---|---|
aws_region |
The AWS region in which the cluster is created.
The default value is, |
aws_preferred_availability_zone |
The preferred availability zone in which the cluster must be created. The default value is |
network_config
Parameter |
Description |
|---|---|
vpc_id |
The ID of the Virtual Private Cloud (VPC) in which the cluster is created.
In this VPC, the |
subnet_id |
The ID of the subnet that must belong to the above VPC in which the cluster is created and it can be a public/private
subnet. Qubole supports multiple subnets. Specify multiple subnets in this format:
|
master_elastic_ip |
It is the Elastic IP address for attaching to the cluster coordinator. For more information, see this documentation. |
bastion_node_public_dns |
Specify the Bastion host public DNS name if private subnet is provided for the cluster in a VPC. Do not specify this value for a public subnet. |
bastion_node_port |
It is the port of the Bastion node. The default value is 22. You can specify a non-default port if you want to access the cluster that is in a VPC with a private subnet. |
bastion_node_user |
It is the Bastion node user, which is ec2-user by default. You can specify a non-default user using this option. |
role_instance_profile |
It is a user-defined IAM Role name that you can use in a dual-IAM role configuration. This Role overrides the account-level IAM Role and only you (and not even Qubole) can access this IAM Role and thus it provides more security. For more information, see Creating Dual IAM Roles for your Account. |
use_account_compute_creds |
Set it to |
cluster_info
Note
An Airflow cluster is a single-node machine and does not have slave nodes and always use On-Demand nodes.
Parameter |
Description |
|---|---|
label |
A list of labels that identify the cluster. At least one label must be provided when creating a cluster. |
cluster_image_version |
|
master_instance_type |
The instance type to use for a cluster coordinator node. The default value is |
slave_instance_type |
The instance type to use for cluster worker nodes. The default value is |
Qubole supports configuring heterogeneous nodes in Hadoop and Spark clusters. It implies that worker nodes can be of different instance types. For more information, see heterogeneous_instance_config and An Overview of Heterogeneous Nodes in Clusters. |
|
min_nodes |
The number of nodes to start the cluster with. The default value is |
max_nodes |
The maximum number of nodes up to which the cluster can be autoscaled. The default value is |
custom_ec2_tags |
It is an optional parameter. Its value contains a <tag> and a <value>. For example, custom-ec2-tags ‘{“key1”:”value1”, “key2”:”value2”}’. A set of tags to be applied on the AWS instances created for the cluster. Specified as a JSON object, for example, {“project”: “webportal”, “owner”: “john@example.com”} It contains a custom tag and value. You can set a custom EC2 tag if you want the instances of a cluster to get that tag on AWS. Tags and values must have alphanumeric characters and can contain only these special characters: + (plus-sign), . (full-stop/period/dot), - (hyphen), @ (at-the-rate of symbol), = (equal sign), / (forward slash), : (colon) and _ (an underscore). The tags, Qubole and alias are reserved for use by Qubole (see Qubole Cluster EC2 Tags (AWS)). Tags beginning with aws- are reserved for use by Amazon. Qubole supports defining user-level EC2 tags. For more information, see Adding Account and User level Default Cluster Tags (AWS). |
customer_ssh_key |
SSH key to use to login to the instances. The default value is, none. (Note: This field is not visible to non-admin users.) The SSH key must be in the OpenSSH format and not in the PEM/PKCS format. |
It is only applicable to the Spark cluster. It is for creating a pacakge management environment. For more information, see env_settings. |
|
It is used to add EBS volumes that are attached to increase storage on instance types that come with low storage but have good CPU and memory configuration. For recommendations on using EBS volumes, see AWS EBS Volumes. EBS Volumes are supported by c3, c4, m3, m4, p2, r3, r4, and x1 slave node type. |
|
Configure the type of nodes for coordinator, minimum, and autoscaling nodes. The supported node types are On-Demand, Spot, and Spot Block. |
|
custom_tags |
It is an optional parameter. Its value contains a <tag> and a <value>. For example, custom-ec2-tags ‘{“key1”:”value1”, “key2”:”value2”}’. A set of tags to be applied on the AWS instances created for the cluster and EBS volumes attached to these instances. Specified as a JSON object, for example, {“project”: “webportal”, “owner”: “john@example.com”}. It contains a custom tag and value. You can set a custom EC2 tag if you want the instances of a cluster to get that tag on AWS. The custom tags are applied to the Qubole-created security groups (if any). Tags and values must have alphanumeric characters and can contain only these special characters: + (plus-sign), . (full-stop/period/dot), - (hyphen), @ (at-the-rate of symbol), = (equal sign), / (forward slash), : (colon) and _ (an underscore). The tags, Qubole and alias are reserved for use by Qubole (see Qubole Cluster EC2 Tags (AWS)). Tags beginning with aws- are reserved for use by Amazon. Qubole supports defining user-level EC2 tags. For more information, see Adding Account and User level Default Cluster Tags (AWS). |
idle_cluster_timeout |
The default cluster timeout is 2 hours. Optionally, you can configure it between 0 to 6 hours that is the value range is
0-6 hours. The unit of time supported is only hour. If the timeout is set at account level, it applies to all clusters
within that account. However, you can override the timeout at cluster level. The timeout is effective on the completion of
all queries on the cluster. Qubole terminates a cluster in an hour boundary. For example, when |
idle_cluster_timeout_in_secs |
After enabling the aggressive downscaling feature on the QDS account, the Cluster Idle Timeout can be configured in
seconds. Its minimum configurable value is Note This feature is only available on a request. Contact the account team to enable this feature on the QDS account. |
node_base_cooldown_period |
With the aggressive downscaling feature enabled on the QDS account, it is the cool down period set in minutes for On-Demand nodes on a Hadoop or a Spark cluster. The default value is 10 minutes. For more information, see Understanding Aggressive Downscaling in Clusters (AWS) or Aggressive Downscaling (Azure). Note This feature is only available on a request. Contact the account team to enable this feature on the QDS account.
You must not set the Cool Down Period to a value lower than |
With the aggressive downscaling feature enabled on the QDS account, it is the cool down period set in minutes for
cluster nodes on a Presto cluster. The default value is Note This feature is only available on a request. Contact the account team to enable this feature on the QDS account. |
|
node_spot_cooldown_period |
With the aggressive downscaling feature enabled on the QDS account, it is the cool down period set in minutes for
Spot nodes on a Hadoop or a Spark cluster. The default value is 15 minutes. For more information, see
Understanding Aggressive Downscaling in Clusters (AWS). It is not applicable to Presto clusters as Note This feature is only available on a request. Contact the account team to enable this feature on the QDS account.
You must not set the Cool Down Period to a value lower than |
root_disk |
Use this parameter to configure the root volume of cluster instances. You must configure its size within this parameter.
The supported range for the root volume size is |
env_settings
It is a configuration for creating a package management environment that is only supported on Spark clusters currently. For more information on the package management through UI, see Using the Default Package Management UI and through API, see Package Management Environment API.
Parameter |
Description |
|---|---|
python_version |
Specify the Python version. Python 2.7 is the default version and Python 3.5 is the other supported version. |
r_version |
Currently, only R Version 3.3 is supported on Qubole. |
name |
It is the name of the environment. |
composition
The cluster composition comprises of the coordinator node, minimum number of nodes, and autoscaling nodes. The supported
node types are ondemand, spotblock, and spot.
The following table describes the supported combinations of coordinator, minimum number of nodes, and autoscaling nodes.
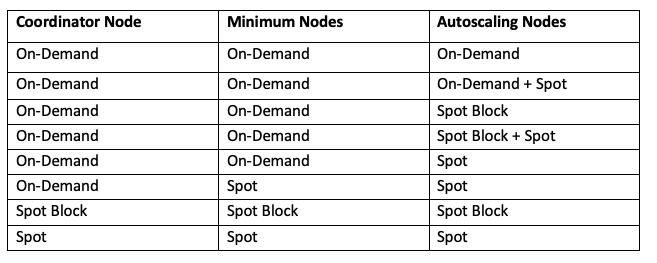
Note
Node Types describes the different node types and possible cluster composition.
Parameter |
Description |
|---|---|
master |
It denotes the coordinator node configuration in the cluster composition. Its configuration must have only one node type. Node Types describes the different types of nodes: ondemand, spot, and spotblock along with associated parameters. A sample payload is added below the parameters of each node type. |
min_nodes |
It denotes the minimum number of nodes’ configuration in the cluster composition. Its configuration must have only one node type. Node Types describes the different types of nodes: ondemand, spot, and spotblock along with associated parameters. A sample payload is added below the parameters of each node type. |
autoscaling_nodes |
It denotes the autoscaling nodes’ configuration in the cluster composition. Add parameters as described in
Node Types describes the different types of nodes: ondemand, spot, and spotblock along with associated parameters. A sample payload is added below the parameters of each node type. |
Node Types
composition - It is a parameter to configure the node type for coordinator, minimum number of nodes, and autoscaling nodes.
The node types that are supported are:
ondemand
Set this value when you want to choose On-Demand nodes
in the cluster composition. The following table describes the associated parameters with the ondemand node type.
Note
Parameters marked in bold below are mandatory. Others are optional and have default values.
Parameter |
Description |
|---|---|
type |
It denotes the type of the node. Its value must be |
percentage |
It denotes the percentage of each node type in case of a homogeneous or hybrid cluster. The supported value range is |
Sample payload for only the ondemand nodes cluster composition.
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
spot
Set this type to use Amazon EC2 spot instances in the cluster composition.
The following table describes the associated parameters with the spot node type.
Note
Parameters marked in bold below are mandatory. Others are optional and have default values.
Parameter |
Description |
|---|---|
type |
It denotes the type of the node. Its value must be |
percentage |
It denotes the percentage of each node type in case of a homogeneous or hybrid cluster. The supported value range is |
timeout_for_request |
The timeout for a spot instance request is in minutes. Qubole supports a lower value of 1 minute to be set for this parameter. Qubole has added a new option for Spot request timeout called |
fallback |
By default, it is set to |
maximum_bid_price_percentage |
The maximum percentage of instances that may be purchased from the AWS Spot market. The default value is |
allocation_strategy |
Use this parameter to set the allocation strategy for spot nodes. The default value is |
Sample payload for the spot nodes cluster composition.
"nodes": [
{
"percentage": 100,
"type": "spot",
"maximum_bid_price_percentage": 100,
"timeout_for_request": "1",
"fallback": "ondemand",
"allocation_strategy": "capacityOptimized"
}
]
spotblock
Spot Blocks are Spot instances that run continuously for a finite duration (1 to 6 hours). They are 30 to 45 percent cheaper than On-Demand instances based on the requested duration. QDS ensures that Spot blocks are acquired at a price lower than On-Demand nodes. It also ensures that autoscaled nodes are acquired for the remaining duration of the cluster. For example, if the duration of a Spot block cluster is 5 hours and there is a need to autoscale at the second hour, Spot blocks are acquired for 3 hours.
Qubole allows you to set spot block as the worker instance type even when the coordinator node type is On-Demand. Configuring Spot Blocks describes
how to configure Spot blocks for autoscaling even when the coordinator node type is On-Demand.
Note
The feature to set Spot blocks as autoscaling nodes even when the coordinator node and minimum worker nodes are On-Demand nodes, is available for a beta access and it is only applicable to Hadoop (Hive) clusters. Create a ticket with Qubole Support to enable it on the account. For more information, see Configuring Spot Blocks.
The following table describes the associated parameters with the spotblock node type.
Note
Parameters marked in bold below are mandatory. Others are optional and have default values.
Parameter |
Description |
|---|---|
type |
It denotes the type of the node. Its value must be |
percentage |
It denotes the percentage of each node type in case of a homogeneous or hybrid cluster. The supported value range is |
timeout |
The timeout for spot blocks is in minutes. The default value is 120 minutes. The accepted value range is 60-360 minutes and the duration must be a multiple of 60. Spot blocks are more stable than spot nodes as they are not susceptible to being taken away for the specified duration. However, these nodes certainly get terminated once the duration for which they are requested for is completed. For more details, see AWS spot blocks. An example of Spot block can be as given below. |
Sample payload for the spotblock cluster composition.
"nodes": [
{
"percentage": 100,
"type": "spotblock",
"timeout": 120
}
]
heterogeneous_instance_config
See An Overview of Heterogeneous Nodes in Clusters for more information.
Parameter |
Description |
|---|---|
memory |
To configure the heterogeneous cluster, you must provide a list of whitelisted set of "node_configuration":{
"heterogeneous_instance_config":{
"memory": {
[
{"instance_type": "m4.4xlarge", "weight": 1.0},
{"instance_type": "m4.2xlarge", "weight": 0.5},
{"instance_type": "m4.xlarge", "weight": 0.25}
]
}
}
}
The following points about the instance types hold good for an heterogeneous cluster:
|
datadisk
Parameter |
Description |
|---|---|
type |
The default EBS volume type is Note For recommendations on using EBS volumes, see AWS EBS Volumes. |
size |
The default EBS volume size is 100 GB for Magnetic/General Purpose SSD volume types and 500 MB for Throughput Optimized HDD/Cold HDD volume type. The supported value range is 100 GB/500 GB to 16 TB. The minimum and maximum volume size varies for each EBS volume type and are mentioned below:
Note For recommendations on using EBS volumes, see AWS EBS Volumes. |
count |
The number of EBS volumes to attach to each cluster instance. The default value is 0. |
encryption |
By default, the encryption is |
Hadoop and Spark clusters that use EBS volumes can now dynamically expand the storage capacity. This relies on Logical Volume Management. When enabled, a volume group is created on this volume group. Additional EBS volumes are attached to the instance and to the logical volume when the latter is approaching full capacity usage and the file system is resized to accommodate the additional capacity. This is not enabled by default. Storage-capacity upscaling in Hadoop/Spark clusters using EBS volumes also supports upscaling based on the rate of increase of used capacity. Note For the required EC2 permissions, see Sample Policy for EBS Upscaling. Here is an "node_configuration" : {
"ebs_upscaling_config": {
"max_ebs_volume_count":5,
"percent_free_space_threshold":20.0,
"absolute_free_space_threshold":100,
"sampling_interval":40,
"sampling_window":8
}
}
See upscaling_config for information on the configuration options. |
upscaling_config
Note
For the required EC2 permissions, see Sample Policy for EBS Upscaling.
Parameter |
Description |
|---|---|
max_ebs_volume_count |
The maximum number of EBS volumes that can be attached to an instance. It must be more than |
percent_free_space_threshold |
The percentage of free space on the logical volume as a whole at which addition of disks must be attempted. The default value is 25%, which means new disks are added when the EBS volume is (greater than or equal to) 75% full. |
absolute_free_space_threshold |
The absolute free capacity of the EBS volume above which upscaling does not occur. The percentage threshold changes as the size of the logical volume increases. For
example, if you start with a threshold of 15% and a single disk of 100GB, the disk would upscale when it has less than 15GB free capacity. On addition of a new node,
the total capacity of the logical volume becomes 200GB and it would upscale when the free capacity falls below 30GB. If you would prefer to upscale only when the
free capacity is below a fixed value, you may use the |
sampling_interval |
It is the frequency at which the capacity of the logical volume is sampled. Its default value is 30 seconds. |
sampling_window |
It is the number of The logical volume is upscaled if, based on the current rate, it is estimated to get full in (sampling_interval + 600) seconds (the additional 600 seconds is because
the addition of a new EBS volume to a heavily loaded volume group has been observed to take up to 600 seconds.) Here is an example how the free space threshold
decrease with respect to the Sample Window and Sample Interval. Assuming the default value of
|
engine_config
Parameter |
Description |
|---|---|
flavour |
It denotes the type of cluster. The supported values are: |
It provides a list of Airflow-specific configurable sub options. |
|
It provides a list of Hadoop-specific configurable sub options. |
|
It provides a list of Presto-specific configurable sub options. |
|
It provides a list of Spark-specific configurable sub options. |
|
It provides a list of HiveServer2-specific configurable sub options. |
hadoop_settings
Parameter |
Description |
|---|---|
custom_config |
The custom Hadoop configuration overrides. The default value is blank. |
The fair scheduler configuration options. |
|
is_ha |
<add description> |
use_qubole_placement_policy |
Use Qubole Block Placement policy for clusters with spot nodes. |
fairscheduler_settings
Parameter |
Description |
|---|---|
fairscheduler_config_xml |
The XML string, with custom configuration parameters, for the fair scheduler. The default value is blank. |
default_pool |
The default pool for the fair scheduler. The default value is blank. |
presto_settings
Parameter |
Description |
|---|---|
presto_version |
It is mandatory and only applicable to a Presto cluster. The supported values are:
|
custom_presto_config |
Specifies if the custom Presto configuration overrides. The default value is blank. |
spark_settings
Parameter |
Description |
|---|---|
zeppelin_interpreter_mode |
The default mode is |
custom_spark_config |
Specify the custom Spark configuration overrides. The default value is blank. |
spark_version |
It is the Spark version used on the cluster. The default version is |
airflow_settings
Note
Parameters marked in bold below are mandatory. Others are optional and have default values.
Parameter |
Description |
|---|---|
dbtap_id |
ID of the data store inside QDS. See Setting up a Data Store (AWS) for more information. |
fernet_key |
Encryption key for sensitive information inside airflow database. For example, user passwords and connections. It must be a 32 url-safe base64 encoded bytes. |
version |
The latest supported Aiflow version is 1.10.2.QDS. |
overrides |
Airflow configuration to override the default settings. Use the following syntax for overrides:
|
deployment_type |
Enables you to select the deployment type among |
remote_sync_location |
If you specify |
git_repo_branch |
If you specify |
git_repo_url |
If you specify |
hive_settings
You can enable HiveServer2 on a Hadoop (Hive) cluster. The following table contains engine_config for enabling
HiveServer2 on a cluster. Other settings of HiveServer2 are configured under the hive_settings parameter. For more
information on HiveServer2 in QDS, see Configuring a HiveServer2 Cluster.
This is an additional setting in the Hadoop (Hive) request API for enabling HiveServer2. Other settings that are explained in Parameters must be added. For details on configuring multi-instance as an option to run HS2 through REST API, see Choosing Multi-instance as an option for running HiveServer2 on Hadoop (Hive) Clusters.
Note
Parameters marked in bold below are mandatory. Others are optional and have default values.
Parameter |
Description |
|
|---|---|---|
hive_settings |
is_hs2 |
Set it to |
hive_version |
It is the Hive version that supports HiveServer2. The values are |
|
hive.qubole.metadata.cache |
This parameter enables Hive metadata caching that reduces split computation time for ORC
files. This feature is not available by default. Create a ticket with
Qubole Support for using this feature on the QDS
account. Set it to |
|
hs2_thrift_port |
It is used to set HiveServer2 port. The default port is |
|
overrides |
Hive configuration to override the default settings. |
|
pig_version |
The default version of Pig is 0.11. Pig 0.15 and Pig 0.17 (beta) are the other supported versions. Pig 0.17 (beta) is only supported with Hive 2.1.1. |
|
pig_execution_engine |
Only with Pig 0.17 (beta), you can use this parameter to set |
|
Choosing Multi-instance as an Option for running HiveServer2
Configuring Multi-instance HiveServer2 describes choosing multi-instance to run HS2 on a Hadoop (Hive) cluster and how to configure it.
This enhancement is available for beta access and it is not available by default. Create a ticket with Qubole Support to enable it on the QDS account.
Parameters for Choosing Multi-instance as an Option to run HS2
Note
Parameters marked in bold below are mandatory. Others are optional and have default values.
Parameter |
Description |
|---|---|
node_bootstrap_file |
You can specify a different node bootstrap file location if you want to change its default location inherited from the associated Hadoop (Hive) cluster. |
ec2_settings |
You can only set elastic IP for the coordinator node of the multi-instance HS2 if you do not want to use the elastic IP of the associated Hadoop (Hive) cluster. For more information, see ec2_settings for Choosing Multi-instance as an Option to run HS2. |
node_configuration |
It has four configuration properties and one of them is mandatory. For more information, see node_configuration for Choosing Multi-instance as an Option to run HS2. |
engine_config |
It denotes the type of the engine. For more information, see engine_config for Choosing Multi-instance as an Option to run HS2. |
node_configuration for Choosing Multi-instance as an Option to run HS2
The coordinator node type of multi-instance HS2 is always m3.xlarge. Create a ticket with
Qubole Support to configure the coordinator node of the multi-instance HS2.
Parameter |
Description |
|---|---|
slave_instance_type |
The instance type to use for cluster worker nodes. The default value is |
initial_nodes |
The default number of nodes is 2. You can only increase the number of nodes even when the cluster is running. However, you cannot reduce the number of nodes or remove them when the cluster is running. |
custom_ec2_tags |
Add custom EC2 tags and values and ensure that you do not add reserved keywords as EC2 tags as described in cluster_info. |
parent_cluster_id |
You must specify the cluster ID of the Hadoop (Hive) cluster on which you want to enable multi-instance as an option to run HS2. |
ec2_settings for Choosing Multi-instance as an Option to run HS2
Parameter |
Description |
|---|---|
master_elastic_ip |
Enter the Elastic IP of Coordinator Node for the multi-instance HS2. When you want to directly (through external BI tools) run queries on multi-instance HS2, you can attach an Elastic IP (EIP) to it and configure the tools to connect to the EIP of multi-instance coordinator. You must add EIP to the multi-instance HS2’s coordinator node because HS2 queries run on the multi-instance HS2 instead of the associated Hadoop (Hive) cluster. |
engine_config for Choosing Multi-instance as an Option to run HS2
Parameter |
Description |
|---|---|
type |
The value of |
monitoring
Note
The Datadog feature is enabled on Hadoop 1, Hadoop (Hive), Presto, and Spark clusters. Once you set the Datadog settings, Ganglia monitoring gets automatically enabled. Although the Ganglia monitoring is enabled, its link may not be visible in the cluster’s UI resources list.
Parameter |
Description |
|---|---|
enable_ganglia_monitoring |
Enable Ganglia monitoring for the cluster. The default value is |
datadog_api_token |
Specify the Datadog API token to use the Datadog monitoring service. The default value is NULL. |
datadog_app_token |
Specify the Datadog APP token to use the Datadog monitoring service. The default value is NULL. |
notifications |
Specify |
security_settings
It is now possible to enhance security of a cluster by authorizing Qubole to generate a unique SSH key every time a cluster is started. This feature is not enabled by default. Create a ticket with Qubole Support to enable this feature. Once this feature is enabled, Qubole starts using the unique SSH key to interact with the cluster. For clusters running in private subnets, enabling this feature generates a unique SSH key for the Qubole account. This SSH key must be authorized on the Bastion host.
Parameter |
Description |
|---|---|
encrypted_ephemerals |
Qubole allows encrypting ephemeral drives on the instances. Create a ticket with Qubole Support to enable the block device encryption. |
ssh_public_key |
SSH key to use to login to the instances. The default value is none. (Note: This parameter is not visible to non-admin users.) The SSH key must be in the OpenSSH format and not in the PEM/PKCS format. |
persistent_security_group |
This option overrides the account-level security group settings. By default, this option is not set but inherits the account-level persistent security group, if any. Use this option if you want to give additional access permissions to cluster nodes. Qubole only uses the security group name for validation. So, do not provide the security group’s ID. You must provide a persistent security group when you configure outbound communication from cluster nodes to pass through a Internet proxy server. |
Sample Request APIs
Here are the samples:
Sample API Request to Create a Hadoop (Hive) Cluster
AL1
curl -X POST -H "X-AUTH-TOKEN:$X_AUTH_TOKEN" -H "Content-Type: application/json" -H "Accept: application/json"
-d
'{
"cloud_config": {
"provider": "aws",
"compute_config": {
"compute_validated": true,
"use_account_compute_creds": true
}
},
"location": {
"aws_region": "us-east-2",
"aws_availability_zone": "<Availability Zone if you want a specific one other than the default value ``Any``>"
},
"network_config": {
"vpc_id": "<VPC-ID>",
"subnet_id": "<subnet-ID>",
"bastion_node_public_dns": "<Bastion-node-public-DNS>",
"bastion_node_port": "<Bastion-node-port>",
"bastion_node_user": "<Bastion-node-user>"
},
"cluster_info": {
"cluster_image_version": "1.latest”,
"master_instance_type": "c3.xlarge",
"slave_instance_type": "c3.2xlarge",
"label": "hadoop-2a",
"min_nodes": 1,
"max_nodes": 4,
"idle_cluster_timeout": 3,
"node_bootstrap": "<node-bootstrap location if you do not want the default S3 location>",
"disallow_cluster_termination": false,
"force_tunnel": true,
"datadisk": {
"count": 1,
"type": "<other than default value>",
"size": "{[
200,
1]",
"encryption": true
},
"composition": {
"master": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
},
"min_nodes": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
},
"autoscaling_nodes": {
"nodes": [
{
"percentage": 100,
"type": "spot",
"maximum_bid_price_percentage": 100,
"timeout_for_request": "1",
"fallback": "ondemand"
}
]
}
}
},
"engine_config": {
"flavour": "hive"
},
"monitoring": {
"ganglia": "true"
}
}' https://api.qubole.com/api/v2.2/clusters/
curl -X POST -H "X-AUTH-TOKEN:$X_AUTH_TOKEN" -H "Content-Type: application/json" -H "Accept: application/json"
-d
'{
"cloud_config": {
"provider": "aws",
"compute_config": {
"compute_validated": true,
"use_account_compute_creds": true
}
},
"location": {
"aws_region": "us-west-2",
"aws_availability_zone": "<Availability Zone if you want a specific one other than the default value ``Any``>"
},
"network_config": {
"vpc_id": "<VPC-ID>",
"subnet_id": "<subnet-ID>",
"bastion_node_public_dns": "<Bastion-node-public-DNS>",
"bastion_node_port": "<Bastion-node-port>",
"bastion_node_user": "<Bastion-node-user>"
},
"cluster_info": {
"cluster_image_version": "1.latest”,
"master_instance_type": "m2.xlarge",
"slave_instance_type": "m2.2xlarge",
"label": "hadoop-hive"
],
"min_nodes": 1,
"max_nodes": 2,
"idle_cluster_timeout": 3,
"node_bootstrap":"<node-bootstrap location if you do not want the default S3 location>",
"disallow_cluster_termination": false,
"force_tunnel": true,
"customer_ssh_key": "<customer_ssh_key>",
"datadisk": {
"encryption": true
},
"composition": {
"master": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
},
"min_nodes": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
},
"autoscaling_nodes": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
}
}
},
"engine_config": {
"flavour": "hive",
"hadoop_settings": {
"custom_hadoop_config": <Hadoop override>
"hive_settings": {
"is_hs2": true,
"hive_version": "2.1.1",
"hive.qubole.metadata.cache":"true",
"hs2_thrift_port": "10007"
"overrides": "hive.execution.engine=tez"
}
}
},
"monitoring": {
"ganglia": true,
}
}' https://api.qubole.com/api/v2.2/clusters/
AL2
curl -X POST -H "X-AUTH-TOKEN:$X_AUTH_TOKEN" -H "Content-Type: application/json" -H "Accept: application/json"
-d
'{
"cloud_config": {
"provider": "aws",
"compute_config": {
"compute_validated": true,
"use_account_compute_creds": true
}
},
"location": {
"aws_region": "us-east-2",
"aws_availability_zone": "<Availability Zone if you want a specific one other than the default value ``Any``>"
},
"network_config": {
"vpc_id": "<VPC-ID>",
"subnet_id": "<subnet-ID>",
"bastion_node_public_dns": "<Bastion-node-public-DNS>",
"bastion_node_port": "<Bastion-node-port>",
"bastion_node_user": "<Bastion-node-user>"
},
"cluster_info": {
"cluster_image_version": "2.latest",
"master_instance_type": "c3.xlarge",
"slave_instance_type": "c3.2xlarge",
"label": "hadoop-2a",
"min_nodes": 1,
"max_nodes": 4,
"idle_cluster_timeout": 3,
"node_bootstrap": "<node-bootstrap location if you do not want the default S3 location>",
"disallow_cluster_termination": false,
"force_tunnel": true,
"datadisk": {
"count": 1,
"type": "<other than default value>",
"size": "{[
200,
1]",
"encryption": true
},
"composition": {
"master": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
},
"min_nodes": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
},
"autoscaling_nodes": {
"nodes": [
{
"percentage": 100,
"type": "spot",
"maximum_bid_price_percentage": 100,
"timeout_for_request": "1",
"fallback": "ondemand"
}
]
}
}
},
"engine_config": {
"flavour": "hive"
},
"monitoring": {
"ganglia": "true"
}
}' https://api.qubole.com/api/v2.2/clusters/
curl -X POST -H "X-AUTH-TOKEN:$X_AUTH_TOKEN" -H "Content-Type: application/json" -H "Accept: application/json"
-d
'{
"cloud_config": {
"provider": "aws",
"compute_config": {
"compute_validated": true,
"use_account_compute_creds": true
}
},
"location": {
"aws_region": "us-west-2",
"aws_availability_zone": "<Availability Zone if you want a specific one other than the default value ``Any``>"
},
"network_config": {
"vpc_id": "<VPC-ID>",
"subnet_id": "<subnet-ID>",
"bastion_node_public_dns": "<Bastion-node-public-DNS>",
"bastion_node_port": "<Bastion-node-port>",
"bastion_node_user": "<Bastion-node-user>"
},
"cluster_info": {
"cluster_image_version": "2.latest",
"master_instance_type": "m2.xlarge",
"slave_instance_type": "m2.2xlarge",
"label": "hadoop-hive"
],
"min_nodes": 1,
"max_nodes": 2,
"idle_cluster_timeout": 3,
"node_bootstrap":"<node-bootstrap location if you do not want the default S3 location>",
"disallow_cluster_termination": false,
"force_tunnel": true,
"customer_ssh_key": "<customer_ssh_key>",
"datadisk": {
"encryption": true
},
"composition": {
"master": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
},
"min_nodes": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
},
"autoscaling_nodes": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
}
}
},
"engine_config": {
"flavour": "hive",
"hadoop_settings": {
"custom_hadoop_config": <Hadoop override>
"hive_settings": {
"is_hs2": true,
"hive_version": "2.1.1",
"hive.qubole.metadata.cache":"true",
"hs2_thrift_port": "10007"
"overrides": "hive.execution.engine=tez"
}
}
},
"monitoring": {
"ganglia": true,
}
}' https://api.qubole.com/api/v2.2/clusters/
Sample API Request to Create an Airflow Cluster
AL1
curl -X POST -H "X-AUTH-TOKEN:$X_AUTH_TOKEN" -H "Content-Type: application/json" -H "Accept: application/json"
-d
'{
"cloud_config": {
"provider": "aws",
"compute_config": {
"compute_validated": true,
"use_account_compute_creds": true
}
},
"location": {
"aws_region": "us-west-1",
"aws_availability_zone": "<Availability Zone if you want a specific one other than the default value ``Any``>"
},
"network_config": {
"vpc_id": "<VPC-ID>",
"subnet_id": "<subnet-ID>",
"bastion_node_public_dns": "<Bastion-node-public-DNS>",
"bastion_node_port": "<Bastion-node-port>",
"bastion_node_user": "<Bastion-node-user>"
},
"cluster_info": {
"cluster_image_version": "1.latest”,
"master_instance_type": "m3.xlarge",
"label": ["Airflow172"],
"min_nodes": 1,
"max_nodes": 1,
"idle_cluster_timeout_in_secs": 3,
"cluster_name": "Airflowcluster",
"node_bootstrap": "<node_bootstrap location>",
"force_tunnel": false,
"customer_ssh_key": <customer SSH Key>,
"composition": {
"master": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
}
}
},
"engine_config": {
"flavour": "airflow",
"airflow_settings": {
"dbtap_id": -1,
"fernet_key": "<Fernet Key>",
"deployment_type": "git",
"git_repo_branch": "master",
"git_repo_url": "https://github.com/example/example.git",
"version": "1.7.2"
}
},
"monitoring": {
"ganglia": true
}
}' https://api.qubole.com/api/v2.2/clusters/
AL2
curl -X POST -H "X-AUTH-TOKEN:$X_AUTH_TOKEN" -H "Content-Type: application/json" -H "Accept: application/json"
-d
'{
"cloud_config": {
"provider": "aws",
"compute_config": {
"compute_validated": true,
"use_account_compute_creds": true
}
},
"location": {
"aws_region": "us-west-1",
"aws_availability_zone": "<Availability Zone if you want a specific one other than the default value ``Any``>"
},
"network_config": {
"vpc_id": "<VPC-ID>",
"subnet_id": "<subnet-ID>",
"bastion_node_public_dns": "<Bastion-node-public-DNS>",
"bastion_node_port": "<Bastion-node-port>",
"bastion_node_user": "<Bastion-node-user>"
},
"cluster_info": {
"cluster_image_version": "2.latest",
"master_instance_type": "m3.xlarge",
"label": ["Airflow172"],
"min_nodes": 1,
"max_nodes": 1,
"idle_cluster_timeout_in_secs": 3,
"cluster_name": "Airflowcluster",
"node_bootstrap": "<node_bootstrap location>",
"force_tunnel": false,
"customer_ssh_key": <customer SSH Key>,
"composition": {
"master": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
}
}
},
"engine_config": {
"flavour": "airflow",
"airflow_settings": {
"dbtap_id": -1,
"fernet_key": "<Fernet Key>",
"deployment_type": "git",
"git_repo_branch": "master",
"git_repo_url": "https://github.com/example/example.git",
"version": "1.7.2"
}
},
"monitoring": {
"ganglia": true
}
}' https://api.qubole.com/api/v2.2/clusters/
Sample API Request to Create a Presto Cluster
AL1
curl -X POST -H "X-AUTH-TOKEN:$X_AUTH_TOKEN" -H "Content-Type: application/json" -H "Accept: application/json"
-d
'{
"cloud_config": {
"provider": "aws",
"compute_config": {
"compute_validated": true,
"use_account_compute_creds": true
}
},
"cluster_info": {
"cluster_image_version": "1.latest”,
"master_instance_type": "c1.xlarge",
"slave_instance_type": "c1.2xlarge",
"label": "Presto1"
"min_nodes": 1,
"max_nodes": 3,
"idle_cluster_timeout": 3,
"node_bootstrap": <node bootstrap location>,
"disallow_cluster_termination": false,
"force_tunnel": true,
"customer_ssh_key": <customer SSH Key>,
"composition": {
"master": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
},
"min_nodes": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
},
"autoscaling_nodes": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
},
{
"percentage": 100,
"type": "spotblock",
"timeout": 120
}
]
}
}
},
"engine_config": {
"flavour": "presto",
"hadoop_settings": {
"custom_hadoop_config": <custom-hadoop-config>,
"use_qubole_placement_policy": true,
"fairscheduler_settings": {
"fairscheduler_config_xml": "<allocations>\n <fairSharePreemptionTimeout>60</fairSharePreemptionTimeout>\n</allocations>"
}
},
"presto_settings": {
"custom_presto_config": "config.properties: query.max-memory-per-node=200GB",
"presto_version": "0.180"
}
},
"monitoring": {
"ganglia": true,
}
}' https://api.qubole.com/api/v2.2/clusters/
AL2
curl -X POST -H "X-AUTH-TOKEN:$X_AUTH_TOKEN" -H "Content-Type: application/json" -H "Accept: application/json"
-d
'{
"cloud_config": {
"provider": "aws",
"compute_config": {
"compute_validated": true,
"use_account_compute_creds": true
}
},
"cluster_info": {
"cluster_image_version": "2.latest",
"master_instance_type": "c1.xlarge",
"slave_instance_type": "c1.2xlarge",
"label": "Presto1"
"min_nodes": 1,
"max_nodes": 3,
"idle_cluster_timeout": 3,
"node_bootstrap": <node bootstrap location>,
"disallow_cluster_termination": false,
"force_tunnel": true,
"customer_ssh_key": <customer SSH Key>,
"composition": {
"master": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
},
"min_nodes": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
},
"autoscaling_nodes": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
},
{
"percentage": 100,
"type": "spotblock",
"timeout": 120
}
]
}
}
},
"engine_config": {
"flavour": "presto",
"hadoop_settings": {
"custom_hadoop_config": <custom-hadoop-config>,
"use_qubole_placement_policy": true,
"fairscheduler_settings": {
"fairscheduler_config_xml": "<allocations>\n <fairSharePreemptionTimeout>60</fairSharePreemptionTimeout>\n</allocations>"
}
},
"presto_settings": {
"custom_presto_config": "config.properties: query.max-memory-per-node=200GB",
"presto_version": "0.180"
}
},
"monitoring": {
"ganglia": true,
}
}' https://api.qubole.com/api/v2.2/clusters/
Sample API Request to Create a Spark Cluster
AL1
curl -X POST -H "X-AUTH-TOKEN:$X_AUTH_TOKEN" -H "Content-Type: application/json" -H "Accept: application/json"
-d
'{
"cloud_config": {
"provider": "aws",
"compute_config": {
"compute_validated": true,
"use_account_compute_creds": true
},
"location": {
"aws_region": "eu-west-1"
},
"network_config": {
"vpc_id": "<vpc-id>",
"subnet_id": "<subnet-id>"
}
},
"cluster_info": {
"cluster_image_version": "1.latest”,
"master_instance_type": "m3.xlarge",
"slave_instance_type": "m3.2xlarge",
"label": "spark24",
"min_nodes": 1,
"max_nodes": 2,
"idle_cluster_timeout": 1,
"node_bootstrap": "node_bootstrap.sh",
"disallow_cluster_termination": false,
"force_tunnel": true,
"customer_ssh_key": "<customer ssh key>",
"datadisk": {
"encryption": false
},
"composition": {
"master": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
},
"min_nodes": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
},
"autoscaling_nodes": {
"nodes": [
{
"percentage": 100,
"type": "spot",
"maximum_bid_price_percentage": 100,
"timeout_for_request": "1",
"fallback": "ondemand"
}
]
}
},
"engine_config": {
"flavour": "spark",
"hadoop_settings": {
"custom_hadoop_config": "mapred.job.hustler.enabled=true",
"use_qubole_placement_policy": false
},
"spark_settings": {
"custom_spark_config": "spark-defaults.conf:\nspark.executor.instances\t 1000",
"spark_version": "2.4-latest"
}
},
"monitoring": {
"ganglia": true
},
"internal": {
"zeppelin_interpreter_mode": "user" }
}
}' https://api.qubole.com/api/v2.2/clusters/
AL2
curl -X POST -H "X-AUTH-TOKEN:$X_AUTH_TOKEN" -H "Content-Type: application/json" -H "Accept: application/json"
-d
'{
"cloud_config": {
"provider": "aws",
"compute_config": {
"compute_validated": true,
"use_account_compute_creds": true
},
"location": {
"aws_region": "eu-west-1"
},
"network_config": {
"vpc_id": "<vpc-id>",
"subnet_id": "<subnet-id>"
}
},
"cluster_info": {
"cluster_image_version": "2.latest",
"master_instance_type": "m3.xlarge",
"slave_instance_type": "m3.2xlarge",
"label": "spark24",
"min_nodes": 1,
"max_nodes": 2,
"idle_cluster_timeout": 1,
"node_bootstrap": "node_bootstrap.sh",
"disallow_cluster_termination": false,
"force_tunnel": true,
"customer_ssh_key": "<customer ssh key>",
"datadisk": {
"encryption": false
},
"composition": {
"master": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
},
"min_nodes": {
"nodes": [
{
"percentage": 100,
"type": "ondemand"
}
]
},
"autoscaling_nodes": {
"nodes": [
{
"percentage": 100,
"type": "spot",
"maximum_bid_price_percentage": 100,
"timeout_for_request": "1",
"fallback": "ondemand"
}
]
}
},
"engine_config": {
"flavour": "spark",
"hadoop_settings": {
"custom_hadoop_config": "mapred.job.hustler.enabled=true",
"use_qubole_placement_policy": false
},
"spark_settings": {
"custom_spark_config": "spark-defaults.conf:\nspark.executor.instances\t 1000",
"spark_version": "2.4-latest"
}
},
"monitoring": {
"ganglia": true
},
"internal": {
"zeppelin_interpreter_mode": "user" }
}
}' https://api.qubole.com/api/v2.2/clusters/