Sample Use Case for Creating a Job
This topic explains how to create a Spark job after setting up the cluster on Talend server. This sample use case explains how to create a job to filter out S3 data using Talend and Qubole.
Prerequisites
The Spark cluster must have been configured on the Talend server. See Configuring Talend to Interact with QDS.
Note
If you want to submit the jobs remotely, you must ensure that the Talend Jobserver is installed.
Parameters for this sample use case:
Name of the cluster connecting to QDS: qubole_hadoop_cluster.
HDFS connection: qubole_hdfs.
Name of the sample job: spark_sample_job.
Note
Hive components are not supported on the Spark cluster. Therefore, you must not use Hive tables in Spark jobs.
Steps
Perform the following steps to create a Spark job:
In the Talend studio, navigate to Repository >> Job Design.
Right-click on Big Data Batch, and select Create Big Data Batch Job.
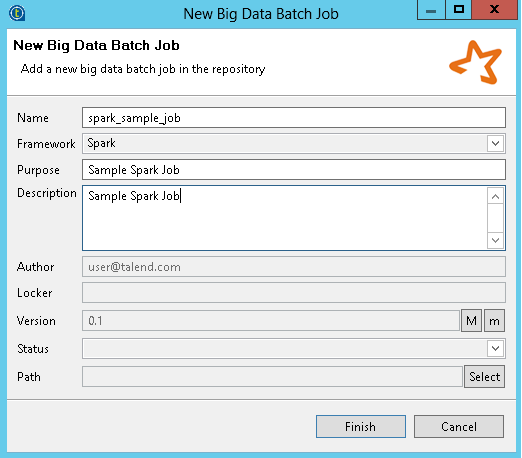
Enter name, purpose, and description for the job in the respective fields as shown in the following figure, and click Finish.
From the new studio editor, navigate to Repository >> Metadata >> Hadoop Cluster.
Select the Hadoop cluster that was configured. Example, qubole_hadoop_cluster.
Drag the HDFS connection (example, qubole_hdfs) to the Designer pane. The Components pop-up box is displayed as shown in the figure.
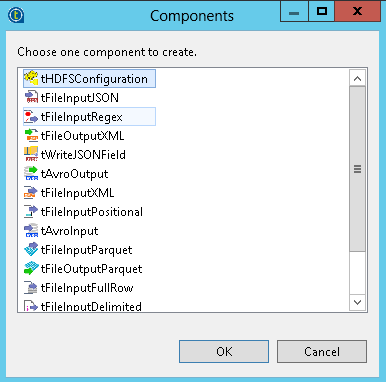
Select tHDFSConfiguration and click OK.
Click Finish.
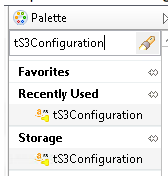
On the Designer pane, search for tS3Configuration from the Palette side bar as shown in the figure.
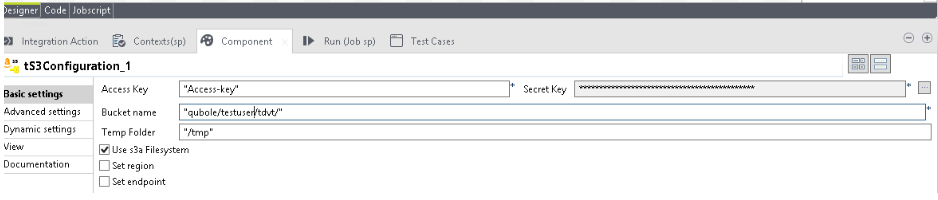
Configure the tS3Configuration component:
Drag the tS3Configuration component to the Designer pane.
Select tS3Configuration, and click on the Component tab.
Enter the access key, secret key, bucket name, and temp folder in the respective fields as shown in the following figure.
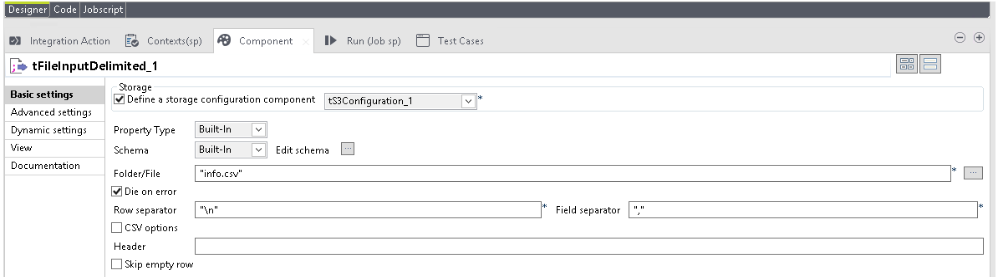
On the Designer pane, search for tFileInputDelimited from the Palette side bar.
Configure tFileInputDelimited component:
Drag the tFileInputDelimited component to the Designer pane.
Select tFileInputDelimited, and click on the Component tab.
Select tS3Configuration_1 for AWS or tAzureFSConfiguration for Azure from Define a storage configuration component.
Enter name of the file that has to be filtered in the Folder/File field.
Select the appropriate Row Separator and Field Separator.
The following figure shows the sample values
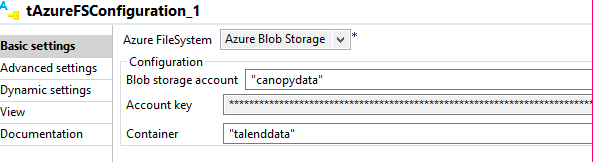
For Azure, update the storage account name, access key, and container for tAzureFSConfiguration as shown in the following figure.
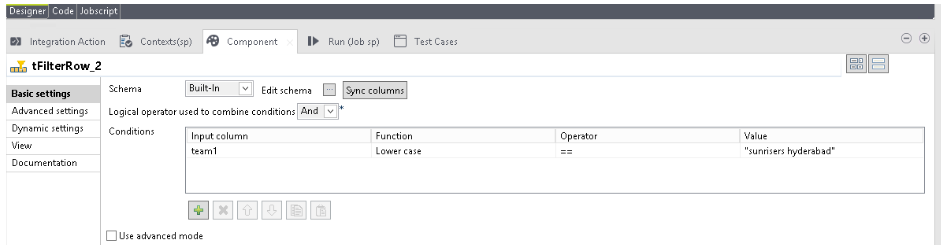
On the Designer pane, search for tFilterRow from the Palette side bar.
Configure tFilterRow component:
Drag the tFilterRow component to the Designer pane.
Select tFilterRow, and click on the Component tab.
Enter the details as shown in the figure.
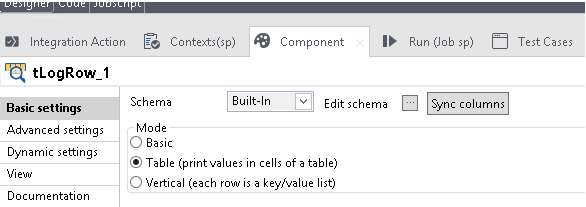
On the Designer pane, search for tLogRow from the Palette side bar.
Configure tLogRow component:
Drag the tLogRow component to the Designer pane.
Select tLogRow, and click on the Component tab.
Enter the details as shown in the figure.
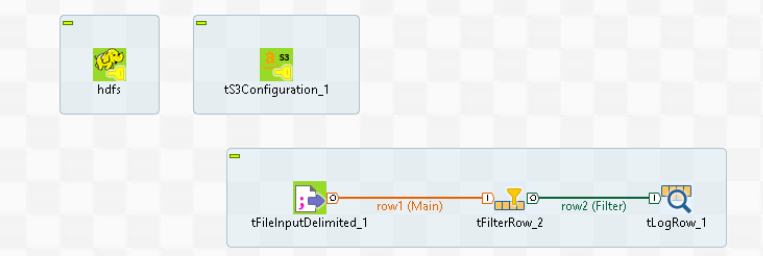
The following figure shows the view of the sample workflow for AWS.
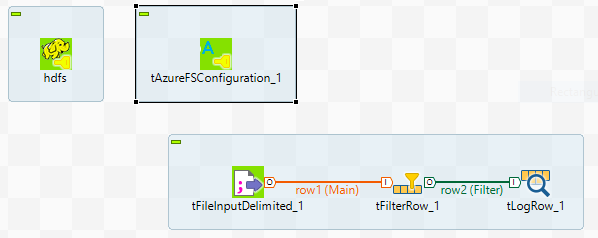
The following figure shows the view of the sample workflow for Azure.
From the Designer pane, click Run (Job spark_sample_job).
Select Target Exec from the left pane. Select the custom job server that was configured as part of configuring Talend.
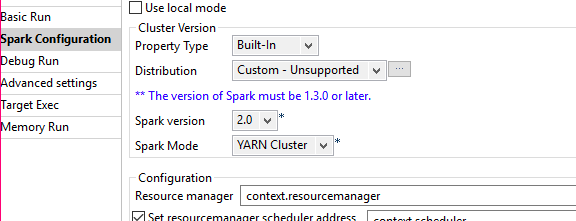
Select Spark Configuration and add Property Type, Spark Version, and Spark Mode as shown in the following figure.
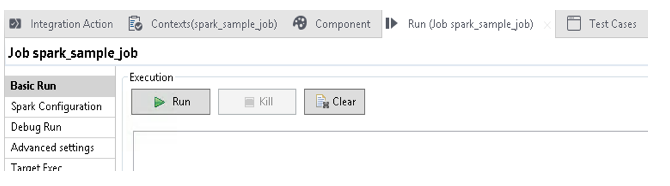
Click on the Run tab. From the navigation pane, select Basic Run, and click Run as shown in the following figure.
The job runs on the cluster and the results are displayed on the console.