Configuring Talend to Interact with QDS
You can use this procedure to configure Talend with Hadoop, Spark, and Hive clusters in QDS.
Before you begin, you must have the public DNS of the cluster’s coordinator node. You must have installed the Talend Jobserver if you want to submit the jobs remotely.
Install Talend Real-time Big Data platform on a Windows AWS instance or a standalone computer that has Windows operating system installed.
Navigate to the Talend Website and search for Qubole Distribution.
Download the Qubole Distribution solution.
Note
The downloaded zip file is used later in defining the connection. Note the path of the downloaded zip file.
Optional: If you want to run the jobs remotely, configure the JobServer.
Create a JobServer cluster.
Create an EC2 instance in the VPC where your Qubole cluster is running.
Upload and run the JobServer.
In the Studio, define this JobServer as a remote server.
Open Window > Preferences, then in the Preferences wizard, open Talend > Run/Debug > Remote.
Click the [+] button twice to add lines. Add the location of your EC2 instance for the JobServer and leave the default values in the Password column.
The following figure shows the Preferences page with sample values.
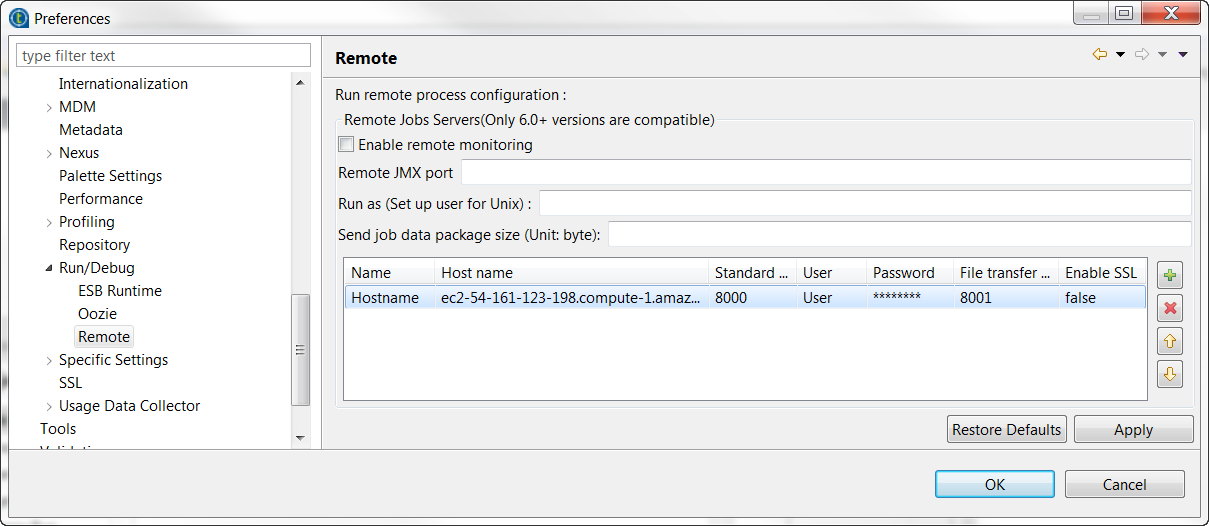
Click Apply and then OK to validate the configuration.
The JobServer is now ready to be used to run your Job remotely.
Define the Qubole connection.
Launch Talend Studio from
C:\Talend\7.0.1\studio.In the Repository tree view, right-click Hadoop cluster under the Metadata node to open the contextual menu.
Select Create Hadoop cluster.
In the step 1 of the wizard, enter the descriptive information about the connection to be created, such as the name of this connection and its purpose.
Note
White spaces and special characters “~”, “!”, “`”, “#”, “^”, “&”, “*”, “\”, “/”, “?”, “:”, “;”, “"”, “.”, “(”, “)”, “’”, “¥”, “’”, “””, “«”, “»”, “<”, “>”. are not supported in the name. These characters are all replaced with “_” in the file system and it might result in duplicate entries.
The following figure shows step 1 of the wizard with sample values.
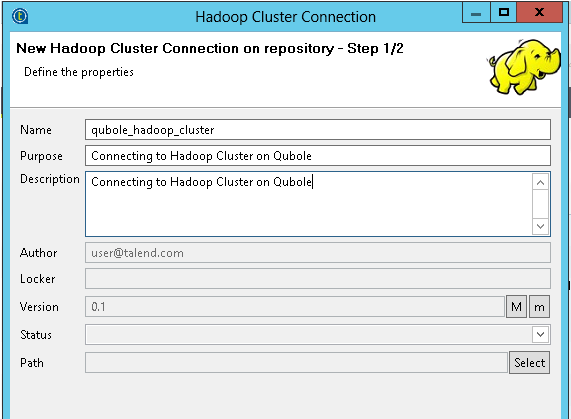
In Import Option section of the wizard, select Enter manually Hadoop services and click Finish.
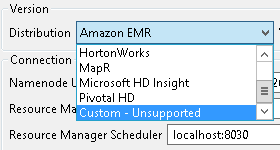
In the step 2 of the wizard, from the Distribution drop-down list, select Custom - Unsupported as shown in the following figure.
Click the […] button to import the Qubole zip file (QuboleExchange.zip). Click OK to validate the import. Click Yes to continue.
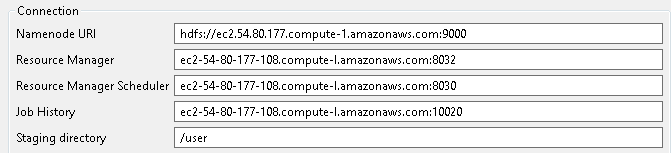
Enter the public DNS of the cluster’s coordinator node along with the port numbers 9000, 8032, 8030, and 10020 in the Namenode URI, Resource Manager, Resource Manager Scheduler, and Job History fields as shown in the following figure.
For Hadoop, use the public DNS of the Hadoop cluster’s coordinator node.
For Spark, use the public DNS of the Spark cluster’s coordinator node.
For Hive, use the public DNS of the Hadoop2 cluster’s coordinator node.
Ensure that Use Yarn is selected.
Enter a valid Talend user name in the User name field.
Click Check Services to verify the connection.
Depending on whether you are adding Hadoop cluster or Spark cluster, perform the appropriate action:
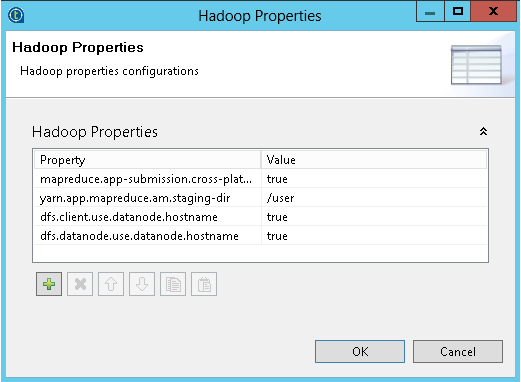
For Hadoop cluster, click the button next to Hadoop Properties, and enter the appropriate values as shown in the following figure:
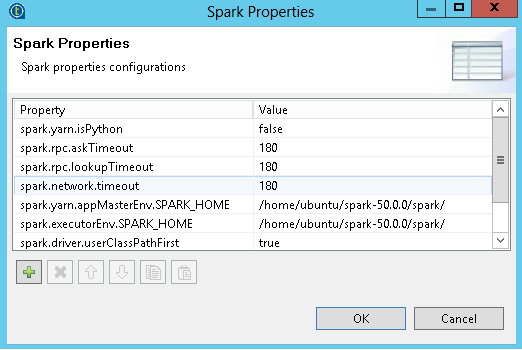
For Spark cluster, select the Use Spark Properties check box, click the button next to the check box, and enter the appropriate values as shown in the following figure:
Click OK. Click Finish on the Hadoop Configuration Import Wizard.
The new connection is displayed under the Hadoop Cluster node in Repository.
Right-click on the newly created cluster and in the contextual menu, select Create HDFS.
Follow the wizard to create the connection to the HDFS service of your Qubole cluster as shown in the following figure.
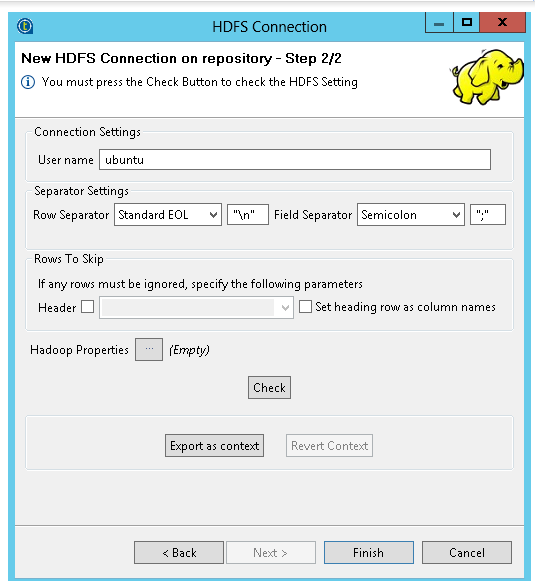
The connection parameters should have been inherited from the parent Qubole connection. Modify the parameters if required.
Click Check to verify the connection to the HDFS service and click Finish.
This HDFS connection is displayed under the Qubole connection you previously defined in Hadoop Cluster node in Repository.
The following figure shows the list of HDFS connections
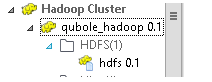
The Qubole connection is now ready to be used in a Talend Job.
Optional: If you want to use Hive connection for the data integration job, perform the following steps:
Right-click on the cluster and in the contextual menu, select Create Hive.
Enter the required fields in the first step of the wizard.
In the second step of the wizard, perform the following steps:
Select DB Type as Hive.
Select Repository from the Hadoop Cluster drop-down list. Select the appropriate Hadoop cluster.
Set Hive Model to Standalone.
Select Use Yarn.
Enter HiveServer2 in the HiveServer Version field.
Enter the appropriate values for Server, Port, and Database fields.
If required, enter the additional JDBC settings, encryption, and Hive properties.
The following figure shows the Step 2/2 of the Hive connection wizard.
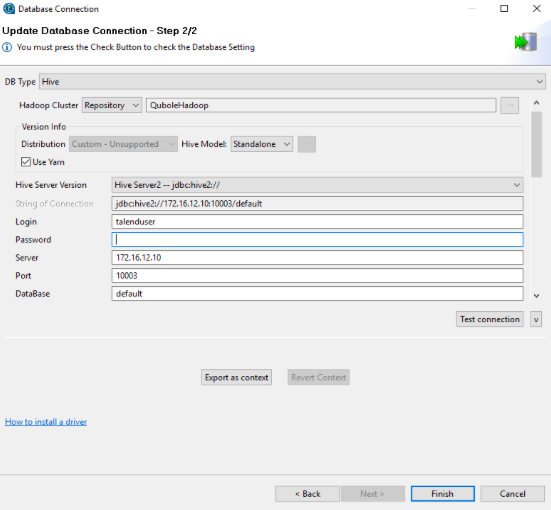
Click Test Connection to verify the connection settings.
Click Finish to complete the Hive connection configuration.