Troubleshooting Spot Instances (AWS)
Identifying Spot Loss
There are three ways to identify when spot loss has occurred, as described below.
Note
For tracing spot node loss in Presto clusters, see Tracing the Query Failure caused by Spot Node Loss.
Autoscaling Log File
In the event of spot loss, the autoscaling log file contains a snippet showing the nodes that are missing due to the spot loss. The autoscaling.log file can be found either through the cluster log page shown below or in the cluster defloc on S3.
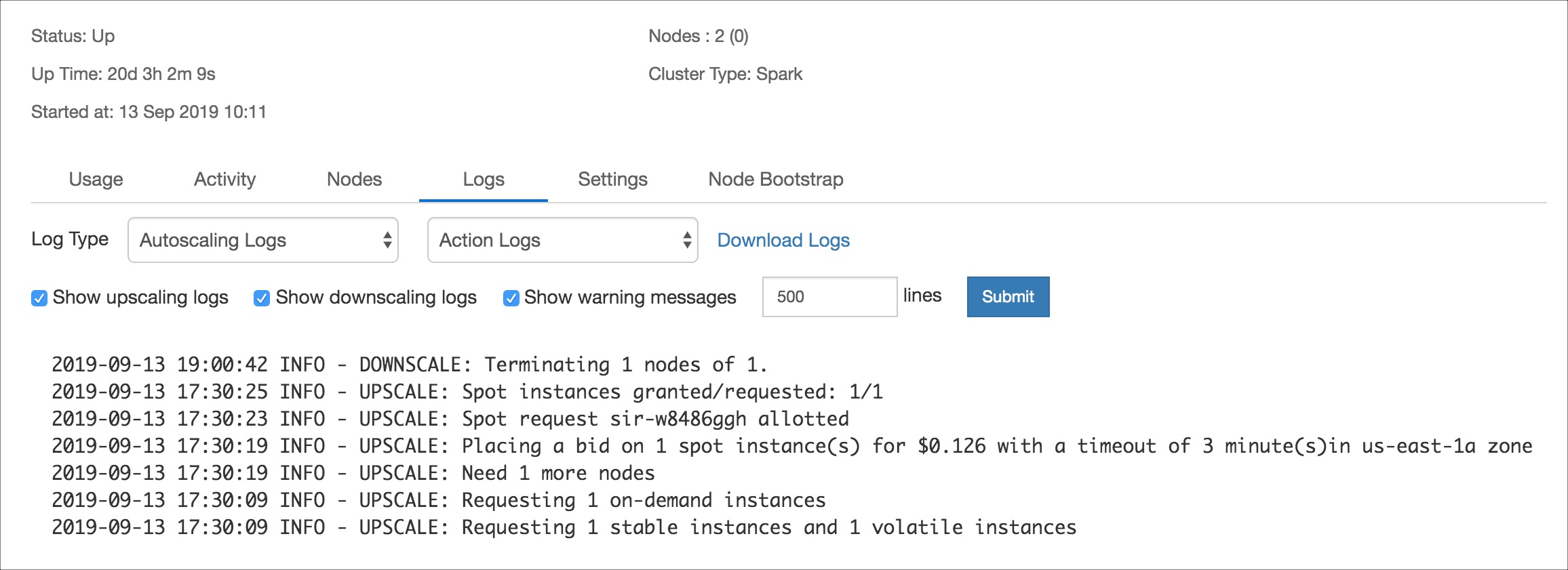
Log Snippet
DEBUG diag.py:106 - get_spot_loss_info - fetching spotloss info from https://qa.qubole.net/api/v2/clusters/71179/current_status
DEBUG apirequest.py:93 - make_api_request_with_retry - request https://qa.qubole.net/api/v2/clusters/71179/current_status
WARNING diag.py:139 - log_spot_loss - Spot nodes were detected as lost at 2017-06-28 07:38:07.708000
Driver Log File
If there is a spot loss on a cluster during the time a job was running on it, you will see connectivity errors on various nodes in the driver log file. This indicates that nodes have are missing due to spot loss.
Log Snippet
dag-scheduler-event-loop INFO DAGScheduler: ShuffleMapStage 9 (save at NativeMethodAccessorImpl.java:0)
failed in 31.307 s due to org.apache.spark.shuffle.FetchFailedException: Failed to connect to <NODE>
This leads to many “NoRouteToHost” exceptions because the nodes have been terminated abruptly, as seen in the following log file:
App > task-result-getter-3 WARN TaskSetManager: Lost task 4.0 in stage 22.3 (TID 790138, 10.108.59.205, executor 229): FetchFailed(BlockManagerId(66, 10.108.63.197, 7337, None), shuffleId=8, mapId=117714, reduceId=4, message=
App > org.apache.spark.shuffle.FetchFailedException: Failed to connect to /10.108.63.197:7337
App > at org.apache.spark.storage.ShuffleBlockFetcherIterator.throwFetchFailedException(ShuffleBlockFetcherIterator.scala:523)
App > at org.apache.spark.storage.ShuffleBlockFetcherIterator.next(ShuffleBlockFetcherIterator.scala:454)
Resource Manager page
Another way to identify spot loss is from the cluster Resource Manager page, which shows the status as “ABOUT_TO_BE_LOST” in the Lost Nodes link:

Resolving Spot Loss
The following are suggestions to help resolve issues related to spot loss. Note that this will not prevent spot loss from happening, as spot loss is random and can happen at any time.
Use multiple secondary instance types (5 to 6) in order to maximize your chances of getting spot nodes.
Use secondary instance types across different instance families, since spot loss often affects the same instance family at a given point in time.
Choose a low Reduce Spot Request Timeout. The longer it takes to acquire a spot node, the higher are the chances of the spot node being taken away due to spot loss.
Reduce the percentage of spot instances on the cluster relative to on demand nodes.