Compaction of Hive Transaction Delta Directories
Frequent insert/update/delete operations on a Hive table/partition creates many small delta directories and files. These delta directories and files can cause performance degradation over time and require compaction at regular intervals. Compaction is the aggregation of small delta directories and files into a single directory.
A set of background processes such as initiator, worker, and cleaner that run within the Hive Metastore Server (HMS), perform compaction in Hive ACID. The compaction is manually triggerable or HMS can automatically trigger it based on the thresholds.
Initiator
The initiator is responsible for identifying the tables or partitions that are due for compaction. You can enable it in HMS
using hive.compactor.initiator.on.
Worker
A worker process handles a single compaction task. Multiple worker processes can run inside an HMS.
hive.compactor.worker.threads determines the number of workers in HMS. Each worker submits the MR/Tez job for
compaction to the cluster (through hive.compactor.job.queue if configured) and waits for the job to finish.
Cleaner
This process is responsible for the deletion of delta/base files after compaction, which are no longer required. In OSS Hive,
the cleaner process is tied up initiator. So, when you enable initiator using hive.compactor.initiator.on,
the cleaner process is also enabled. Qubole provides you control over the cleaner process to overcome the limitation of
OSS Hive. In Qubole Hive ACID, you can disable the cleaner process using following configurations:
Set
metastore.compactor.force.disable.cleanertotrueto disable the cleaner thread at HMS startup. Its default value isfalse.Set
NO_CLEANUPtofalsein the table properties as shown in the following command to disable the table-level cleanup and prevent the cleaner process from automatically cleaning obsolete directories/files.ALTER TABLE <tablename> SET TBLPROPERTIES('NO_CLEANUP'=TRUE);To enable the table-level cleanup on the table, use this command.
ALTER TABLE <tablename> SET TBLPROPERTIES('NO_CLEANUP'=FALSE);
You can delay the obsolete data cleanup after compaction by setting hive.compactor.delayed.cleanup.enabled=true.
You can also configure a delay in the cleanup using the CLEANER_RETENTION_TIME_SECONDS table property.
Delta File Compaction
Hive ACID supports these two types of compactions:
Minor compaction: It takes a set of existing delta files and rewrites them to a single delta file per bucket.
Major compaction: It takes one or more delta files and the base file for the bucket, and rewrites them into a new base file per bucket. Major compaction is more expensive but it is more effective.
For more information, see Compaction.
The following sections describe configuration and how to view compaction and handle cluster resources:
Configuring Compaction
You can set Hive compaction properties on the Hive 3.1.1 (beta) cluster or on the maintenance Hive 3.1.1 (beta) cluster as required. (For more info, see Effectively Handling Cluster Resources for Compaction.)
For configuring compaction properties, edit the cluster’s Advanced Configuration. Pass the following Hive compaction properties in HIVE SETTINGS > Override Hive Configuration.
hive.compactor.initiator.on=true
hive.compactor.worker.threads=<>
hive.compactor.delta.pct.threshold=<>
hive.compactor.delta.num.threshold=<>
For more info, see Hive compaction properties.
Viewing Compaction
After configuring compaction properties, you can check how compaction works as illustrated below:
Create an ACID table and insert a few rows as illustrated below.
If you do a listing on the table location, you can see delta directories created as illustrated below.
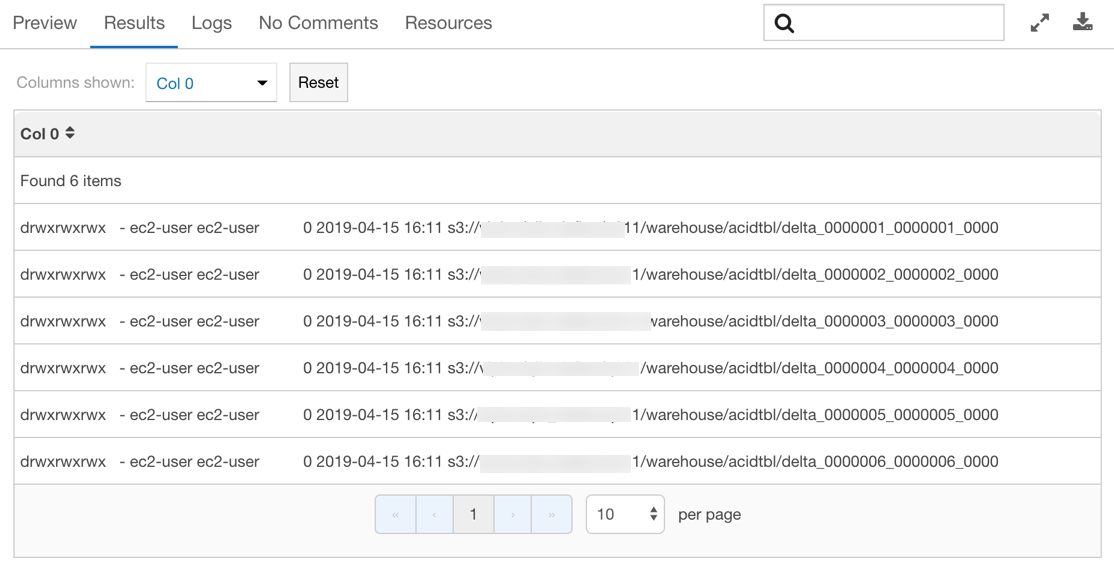
In the above example, there are 6 delta directories and let us say that
hive.compactor.delta.num.thresholdis configured as4. If the number of delta directories exceeds 4, auto compaction is triggered.You can check the compaction status by running the
show compactions;command.The following figure is an example of an initiated compaction.

After the initiation, a worker thread (runs inside HMS) picks up compaction and a Hadoop job is launched. You can track the job’s progress by using the
HadoopJobId, which is listed in ResourceManager page. The following figure is an example of a compaction that is in progress.
The following figure is an example of a successful compaction.

Effectively Handling Cluster Resources for Compaction
As a compaction job also requires cluster resources, compaction jobs can affect workloads running on a cluster. Qubole recommends configuring a maintenance cluster to handle compaction.
You can create a maintenance Hive 3.1.1 (beta) cluster and configure compaction thresholds on it. You can schedule its bring up through Qubole Scheduler to start daily. HMS running on this maintenance cluster will poll the metastore to identify tables and partitions for compaction automatically. You can also submit a compaction request through an ALTER TABLE command. After pending compaction jobs complete, you can terminate the maintenance Hive cluster or let it automatically terminate after the idle cluster timeout period expires.
Note
A maintenance cluster is not necessarily required but it is recommended. If you are not using a maintenance cluster, you can configure a regular Hive 3.1.1 cluster to perform compactions as well.
Create a Hive 3.1.1 (beta) cluster by navigating to Clusters UI. For more details, see Required Setup.
Understanding Cluster Operations describe how to add a cluster and Adding or Changing Settings (AWS) describes how to configure a cluster.
Recommended Hive Configuration for the Regular Cluster
Qubole recommends you to only enable the initiator process on the regular cluster and set a threshold value each for
major and minor compactions. As the initiator only identifies a potential candidate for compaction and adds them into
compaction_queue, it does not use much resources. In addition, as the cleaner process is tied up with initiator by
default, it also runs on the regular cluster and cleans obsolete files/directories in the background.
These are sample Hive properties that you can override in Advanced Configuration > HIVE SETTINGS > Hive overrides of the regular cluster.
hive.metastore.uris=thrift://localhost:10000
hive.support.concurrency=true
hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager
hive.exec.dynamic.partition.mode=nonstrict
hive.compactor.initiator.on=true
hive.compactor.delta.num.threshold=10
hive.compactor.delta.pct.threshold=0.1f