Understanding Different Ways to Run Hive
On QDS, you can run Hive in three different ways that are as follows:
QDS supports Hive version 2.1.1 on all the above ways of running Hive. For more information on versions, see Understanding Hive Versions.
Pros and Cons of Each Method to Run Hive provides a table that lists pros, cons, and recommended scenario of each method.
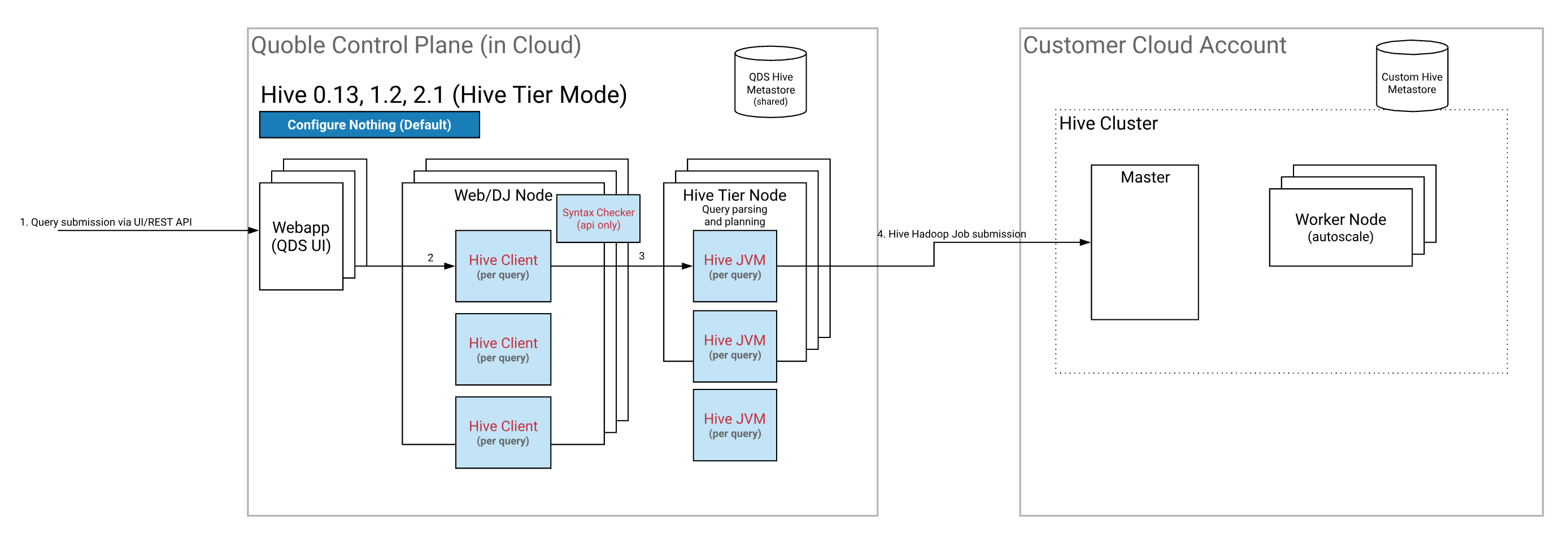
Running Hive through QDS Servers
Here is the architecture that depicts how Hive runs through QDS Servers. Pros and Cons of Each Method to Run Hive provides a table that lists pros, cons, and recommended scenario of this method.
Running Hive on the Coordinator Node
Here is the architecture that depicts how Hive runs on the cluster’s Coordinator node. Pros and Cons of Each Method to Run Hive provides a table that lists pros, cons, and recommended scenario of this method.
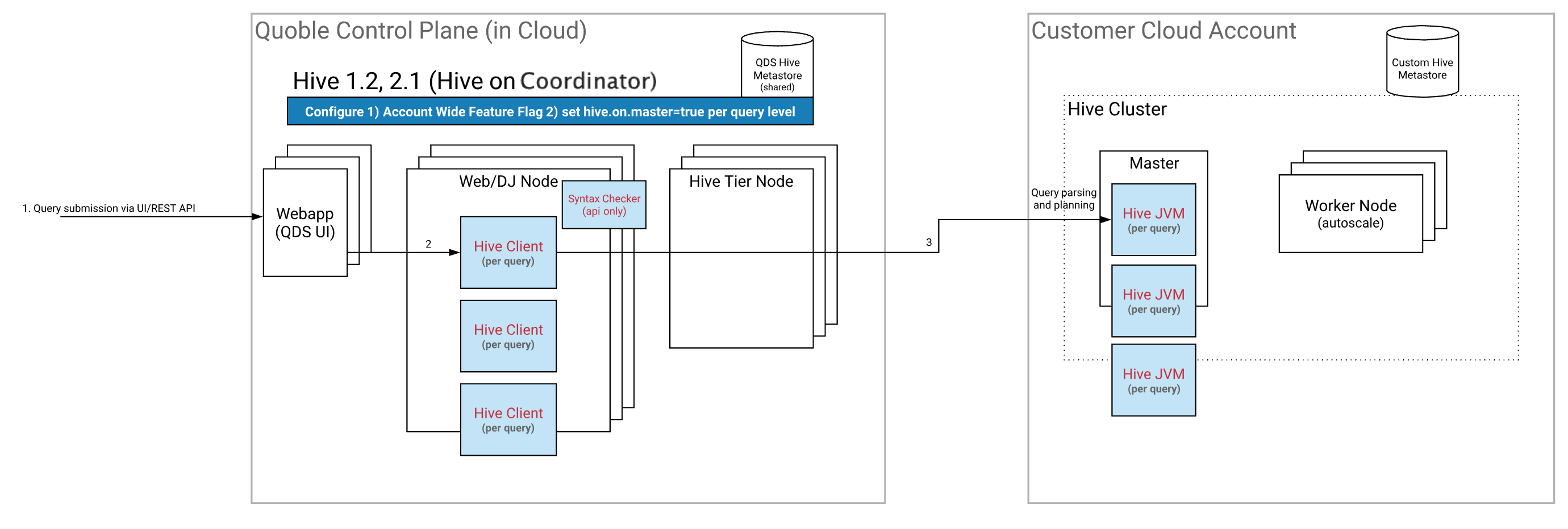
Qubole allows you to write to local filesystem and add custom Jars/UDFs by default when the query runs on the HiveServer2 or Hive-on-Coordinator mode.
Running Hive with HiveServer2 on the Coordinator Node
Here is the architecture that depicts how Hive runs on HiveServer2 (HS2). Pros and Cons of Each Method to Run Hive provides a table that lists pros, cons, and recommended scenario of this method.
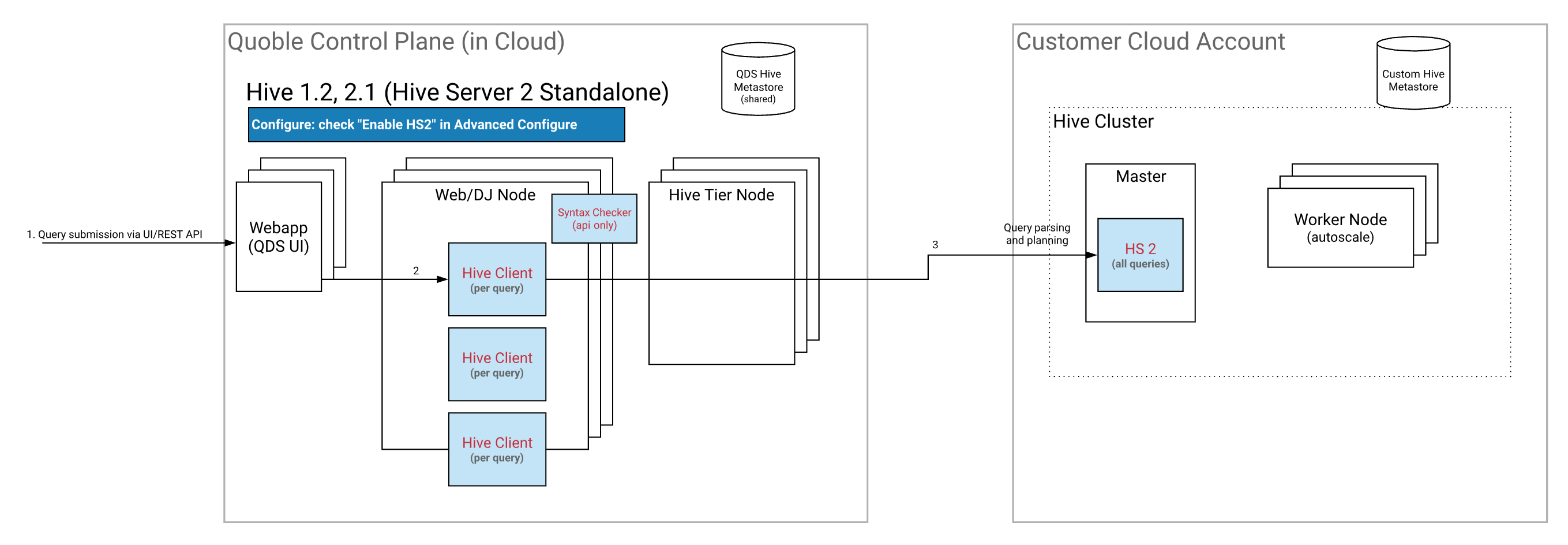
Qubole allows you to write to local filesystem and add custom Jars/UDFs by default when the query runs on the HiveServer2 or Hive-on-Coordinator mode.
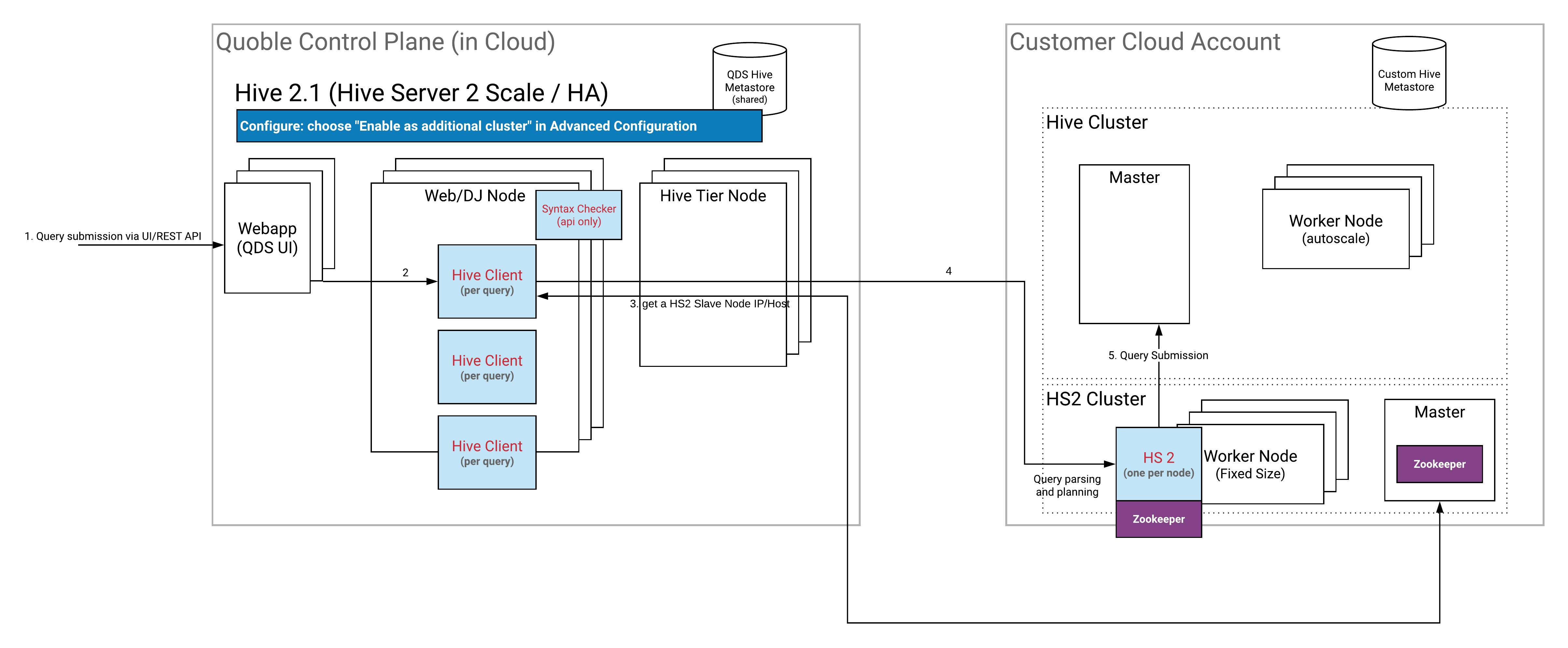
Running Hive with Multi-instance HiveServer2
Here is the architecture that depicts how Hive runs on multi-instance HiveServer2 (HS2). Pros and Cons of Each Method to Run Hive provides a table that lists pros, cons, and recommended scenario of this method.
Pros and Cons of Each Method to Run Hive
This table describes the pros, cons, and recommendation of each method of running Hive.
Method |
Pros |
Cons |
Recommended Scenario |
|---|---|---|---|
Running Hive through QDS Servers |
|
|
|
Running Hive on the Coordinator Node |
|
|
This method is recommended when you:
|
Running Hive with HiveServer2 on the Coordinator Node |
|
|
This method is recommended when you:
|
Running Hive with multi-instance HiveServer2 |
|
|
This method is recommended when you:
|