Understanding Automatic Statistics Collection in Qubole
Presto, Apache Spark, and Apache Hive can generate more efficient query plans with table statistics. For example, Spark, as of version 2.1.1, performs broadcast joins only if the table size is available in the table statistics stored in the Hive Metastore (see spark.sql.autoBroadcastJoinThreshold). Broadcast joins can have a dramatic impact on the run time of everyday SQL queries where small dimension tables are joined frequently. The Big Bench tuning exercise from Intel reported a 4.22x speedup by turning on broadcast joins for specific queries.
In Qubole Data Service (QDS), all query engines use Hive Metastore as the catalog. If the Hive Metastore contains statistics, then all query engines can use them for query planning as explained above. But table statistics collection is not automatic. One of the goals of the Qubole platform is to apply automation to help users achieve maximum performance and efficiency. This topic describes how Qubole has automated Table Statistics collection in QDS. It covers:
Understanding the Pros and Cons of Apache Hive Table Statistics
The Apache Hive Statistics wiki page describes the list of statistics that can be computed and stored in the Hive metastore. Statistics collection is not automated, and the pros and cons are described in this table.
Solution |
Pros |
Cons |
|---|---|---|
The user sets hive.stats.autogather=true to gather statistics automatically during INSERT OVERWRITE queries. |
Supported in Hive |
Cons include:
It does not catch direct writes to cloud object storage locations for external tables. |
The user schedules ANALYZE TABLE COMPUTE STATISTICS The user picks up a few tables as wanted to keep statistics updated and then uses Qubole Scheduler (or an external cron job) to run the COMPUTE STATISTICS statement on these tables periodically. |
Engine Agnostic |
|
In a bid to overcome the disadvantages of table statistics of open source described above, Qubole has decided to provide automated statistics collection into the QDS platform as a service.
Note
Qubole supports viewing and killing the automatic statistics command through the API as described in Automatic Statistics Collection API.
Understanding Qubole Statistics Collection Service
These are the requirements for using the collection service:
Use the
ANALYZE COMPUTE STATISTICSstatement in Apache Hive to collect statistics.Trigger
ANALYZEstatements for DML and DDL statements that create tables or insert data on any query engine.ANALYZEstatements must be transparent and not affect the performance of DML statements.ANALYZE COMPUTE STATISTICScomes in three flavors in Apache Hive.
The three flavors of ANALYZE COMPUTE STATISTICS are described in this table.
SQL Statement Example |
Metadata Collected |
Impact on Cluster |
|---|---|---|
|
Number of files and physical size in bytes |
It is very fast and nearly zero impact on the cluster’s running workloads. |
|
Number of files, physical size in bytes, and number of rows |
It scans the entire table or partition specified and has moderate impact. |
ANALYZE TABLE [db_name.]tablename
|
Number of distinct values, NULL values, and TRUE and FALSE (BOOLEANS case). Minimum/maximum values and average/maximum length of the column. |
It has a significant impact. |
Each flavor requires different compute resources. Qubole also supports partial/full scans to gather AutoStats of Hive tables. Qubole allows you to decide the appropriate statistics for each table. Currently, you can choose the flavor, partial scan or full scan at the account level. In the future, Qubole plans to allow you to configure the flavor at a table or schema level. Create a ticket with Qubole Support to enable this feature on the QDS account.
This architectural diagram shows how ANALYZE COMPUTE STATISTICS statements are triggered in QDS.
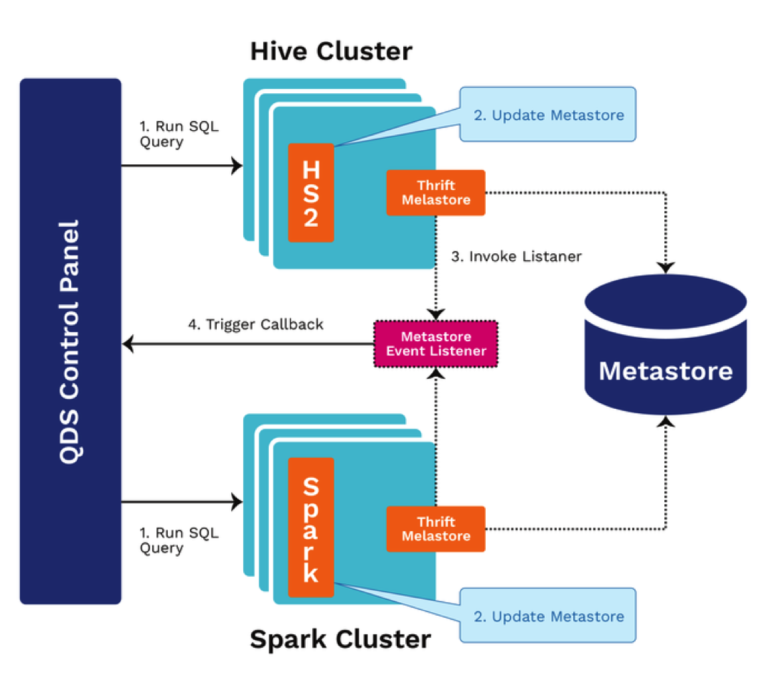
Here is the command’s computation process:
A user issues a Hive or Spark command.
If this command is a DML or DDL statement, the metastore is updated.
A custom MetastoreEventListener is triggered.
The command is run just like any other Hive command.
Qubole has seen a significant performance boost for analytic queries in Apache Hive and SparkSQL using table statistics and it is working with the Presto community to incorporate statistics in the Presto query planning as well.
Qubole has announced the launch of AIR (Alerts, Insights, Recommendations). Automatic Statistics Collection plays a key role in the Qubole’s autonomous data platform. Some examples of use cases within AIR are:
Viewing table statistics in the preview.
The QDS platform can give recommendations and insights on better partitioning or data organization strategies to data engineers, architects, or admins based on statistics.
Supported Versions
Qubole supports Automatic Statistics Collection from Hive version 2.1.1 onwards and any Presto/Spark version using Hive Metastore Server.
Allowing and Denying Hive Tables
Qubole supports allowing and denying Hive tables using a wildcard pattern for automatic table statistics. Create a ticket with Qubole Support to enable allowing and denying of tables.
You can create a ticket with Qubole Support to configure tables on which you want to collect statistics and you can configure the tables to be ignored by listing such tables. The two configuration properties allow a comma-separated list of wildcard patterns, which are matched against the corresponding table for AutoStats. Statistics are collected on tables matching allowed list and not matching denied list. Some examples of the wildcard patterns are described in the following table.
Note
If a schema/database is not mentioned in the wildcard pattern for allowing/denying Hive tables, then Qubole considers the default schema/database.
Wildcard Pattern |
Description |
|---|---|
abc |
It matches the |
*.abc |
It matches the |
xyz.* |
It matches all Hive tables in the |
Running the AutoStats Command using a Single User
Users can configure to run AutoStats commands as a single pre-designated user irrespective of the user whose query
triggers the AutoStats command. Create a ticket with Qubole Support to configure
users to run AutoStats commands. This allows necessary permissions (SELECT and INSERT) granted to this
single user for required tables when Hive Authorization or Ranger is configured in the account.
If a single user is not set, then AutoStats commands are run using system-admin (or a user with admin privileges) of the account. The Hive bootstrap of the selected user is run before running the AutoStats Hive query.
Using a Maintenance Cluster for AutoStats
While the AutoStats command can run on any cluster, Qubole recommends running it in a separate maintenance cluster due to the following reasons:
There is a reduction in cost as one can afford to have 100% spot cluster for autoscaling nodes. You can choose the coordinator node to be the On-Demand type for collecting statistics with aggressive downscaling thresholds.
There is a better isolation for AutoStats queries, which ensures that it does not interfere with the core query workload
There is a better control on the rate at which statistics is updated as the AutoStats command only runs when the maintenance cluster is up.
It is easier to identify the QCUH used in collecting statistics for tables.
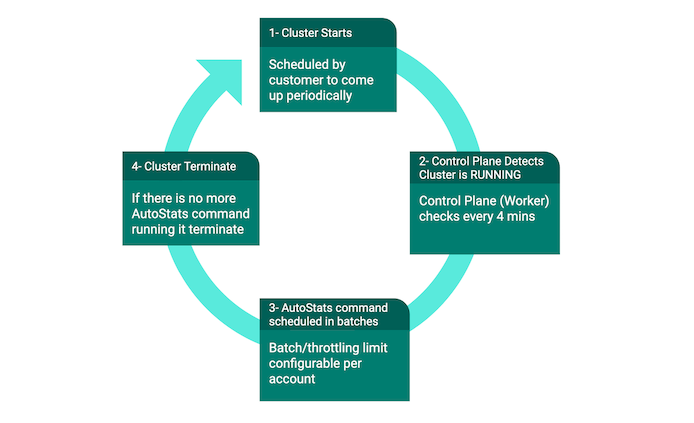
Maintenance Cluster Lifecycle
You must schedule the maintenance cluster to automatically start up at regular intervals so that the AutoStats command
can run on it. AutoStats commands are not triggered unless the cluster is in the RUNNING state. The commands are
queued in QDS Control Plane until the cluster comes up. The commands are executed in batches on the maintenance cluster, which
can run 20 commands by default that is only 20 statistics commands per account can run in parallel at a given time. All
AutoStats commands, which were queued before the current maintenance cluster instance’s start time are scheduled on this
instance. With automatic cluster termination of the maintenance cluster, if no more AutoStats command is scheduled on the
cluster, it is terminated automatically. The following figure illustrates the life cycle of the maintenance cluster.
Recommended Configuration for a Maintenance Cluster
These are the recommended configuration for a maintenance cluster:
Cluster Type: Hadoop (Hive) and a non-HiveServer2 with Hive 2.1.1 and later versions.
Number of nodes: Depending on the workload, the cluster can run queued statistics commands for the set time period. You can begin with number of nodes as low as 2 or 3 and increase as required based on the workload.
Node composition: You can set the spot node type for worker nodes to reduce cost.
Ideal cluster timeout: The ideal cluster timeout can be as a minimum as 5 minutes.