Configuring a Spark Notebook
This page covers the following topics:
For using the Anaconda Python interpreter, see Using the Anaconda Interpreter.
Configuring Per-User Interpreters for Spark Notebooks
Per-user interpreters provide each Spark Notebook user with a dedicated interpreter, ensuring a fair distribution of cluster resources among running interpreters. This is called user mode; see also Using the User Interpreter Mode for Spark Notebooks.
Advantages of User Mode
User mode provides each user with a dedicated interpreter. Advantages of this include:
Each user’s customizations of the interpreter properties are preserved; for example:
Configured cluster resources, such as driver memory (
spark.driver.memory)The default interpreter type (
zeppelin.default.interpreter)Dependencies such as Maven artifacts.
Bottlenecks are reduced because cluster resources are shared among running interpreters.
Each user gets a dedicated Spark session (Spark versions 2.0.0 and later) or SparkContext.
User mode is best suited to an environment in which several users are likely to be using notebooks to run jobs and applications at any given time. But it does not unnecessarily restrict access to cluster resources when one only one or a few jobs are running; see Important Resource Considerations for more discussion.
Qubole recommends that you use user mode because it provides better performance for individual users, and allows the most efficient and cost-effective use of cluster resources.
Enabling User Mode
To enable user mode, proceed as follows.
Note
If this is a new QDS account, user mode is enabled by default, so you can skip the steps that follow.
All the interpreters that were available in legacy mode continue to be available after you switch the cluster to user mode.
Navigate to the Clusters page in QDS and clone your Spark cluster (select Clone from the drop-down menu next to the cluster at the right of the screen.) Cloning the cluster is not required, but Qubole recommends it.
Select the Edit button for your new Spark cluster.
From the drop-down list next to Zeppelin Interpreter Mode, choose user.
If the cluster is already running, restart it to apply the change.
To switch the cluster back to legacy mode, simply repeat steps 2-4 above, setting Zeppelin Interpreter Mode to legacy instead of user. Any interpreters created in user mode continue to be available; users should make sure the interpreter they want to use is at the top of the list.
You can also set interpreter modes through REST API calls. For more information, see spark_settings.
How User Interpreter Mode Works
When user mode is enabled, an interpreter is created automatically for each user who runs a notebook.
Each interpreter is named as follows: user_<user's_email_name>_<user's_email_domain> (user is a literal constant);
for example, for a user whose email address is abc@xyz.com, the interpreter name is set to user_abc_xyz. (The email
address is also stored in spark.yarn.queue.)
Default properties are set by QDS; users can change the defaults, but there is currently no way for you, as the system administrator, to assign new global defaults.
Users can also create additional interpreters.
Important Resource Considerations
Spark Executors: When a user runs a notebook with an interpreter in user mode, the interpreter launches executors as needed, starting with the minimum configured for the interpreter (
spark.executor.instances) and scaling up to the configured maximum (spark.dynamicAllocation.maxExecutors). These values vary depending on the instance type, and are derived from thespark-defaults.conffile. You should assess these values, and particularlyspark.dynamicAllocation.maxExecutors, in terms of the day-to-day needs of your users and their workflow, keeping the following points in mind:QDS will never launch more than
spark.dynamicAllocation.maxExecutorsfor any interpreter, regardless of how many are running. This means that when only one or a few interpreters are running, cluster resources (that could be employed to launch more executors and speed up jobs) may go unused; so you need to make sure that the default maximum is not set too low.Conversely, because QDS will autoscale the cluster if necessary to meet the demand for executors, you also need to make sure that
spark.dynamicAllocation.maxExecutorsis not set too high, or you risk paying for computing resources (executors) that are not needed.Once you have determined the best default, you should discourage users from changing it for an individual interpreter without consulting their system administrator.
YARN Fair Scheduler: In user mode, QDS configures the YARN Fair Scheduler to allocate executors (with their underlying cluster resources such as memory and processors) among running interpreters; and enables preemption (
yarn.scheduler.fair.preemption). These controls come into play when the cluster resources are fully stretched– that is, when the maximum number of nodes are running the maximum number of executors.You do not need to configure the Fair Scheduler manually as described here.
Spark cluster coordinator node: Each interpreter takes up memory (2 GB by default) in the Spark driver, which runs on the Spark cluster coordinator node. The load on the coordinator node is likely to be greater in the user mode than in the legacy mode because in user mode each user is running a dedicated interpreter instance.
As a result, you might have to increase the capacity of the coordinator node by choosing a larger instance type, considering the number of interpreters running at any given time.
Loading Dependent Jars
To make required jars accessible to all Zeppelin notebooks, copy the dependent jar file to /usr/lib/spark/lib on
all nodes (through node_bootstrap.sh).
Loading Dependent Jars Dynamically in a Notebook
Zeppelin has introduced an UI option on the Interpreters page to add a dependency. The following figure shows a create interpreter page with the Dependencies text field.
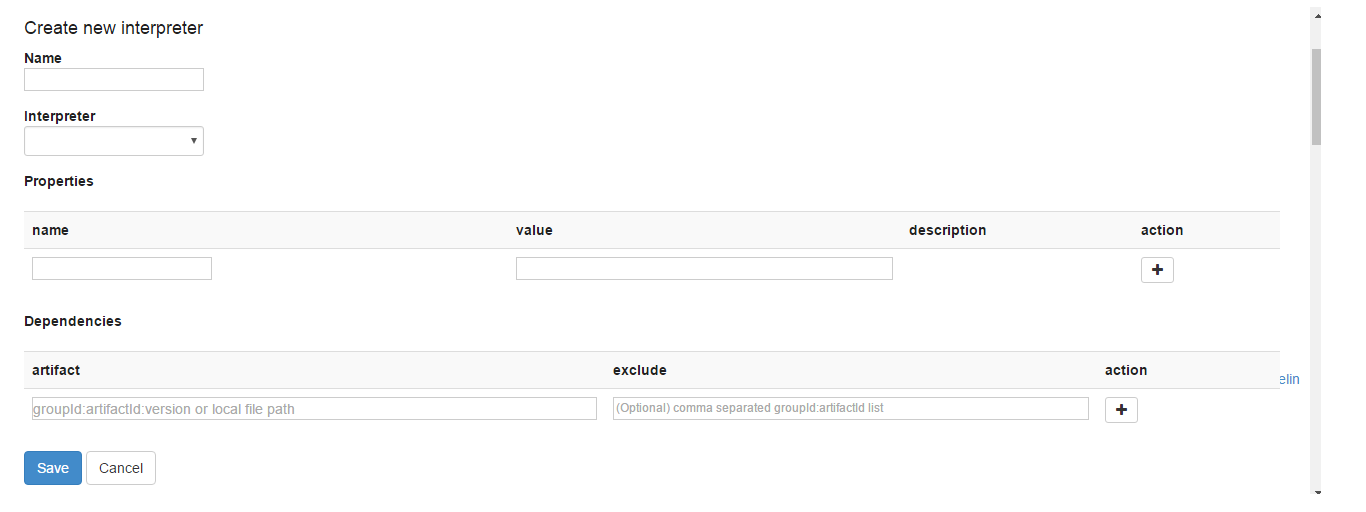
Add the artifact in the format <groupID>:<artifactID>:<version> or the local path in the artifact text field.
You can exclude artifacts if any. Click + icon to add another dependency. Click Save to add the dependency along
with other Spark interpreter changes (if any). The Dependencies UI option is the same for creating and editing an
existing Spark interpreter.
You can add remote Maven repositories and add dependencies in the configured remote repositories.
You can also use the %dep or %spark.dep interpreter to load jars before starting the Spark interpreter. You must enable the dynamic interpreter
in a paragraph and subsequently use the %spark interpreter in a new paragraph.
The following are interpreter examples.
Example 1
The following example is for loading a Maven Artifact.
Paragraph 1
%dep
z.reset()
z.load("com.google.code.facebookapi:facebook-java-api:3.0.4")
OR
%spark.dep
z.reset()
z.load("com.google.code.facebookapi:facebook-java-api:3.0.4")
Paragraph 2
%spark
import com.google.code.facebookapi.FacebookException;
import com.google.code.facebookapi.FacebookWebappHelper;
class Helloworld{
def main1(args:Array[String])
{
println("helloworld")
}
Example 2
The following example is for loading a Spark CSV jar.
import org.apache.spark._
import org.apache.spark.sql._
val sparkSession = SparkSession
.builder()
.appName("spark-csv")
.enableHiveSupport()
.getOrCreate()
import sparkSession.implicits._
val squaresDF = sparkSession.sparkContext.makeRDD(1 to 100).map(i => (i, i * i)).toDF("value", "square")
val location ="s3://bucket/testdata/spark/csv1"
squaresDF.write.mode("overwrite").csv(location)
sparkSession.read.csv(location).collect().foreach(println)
Configuring Spark SQL Command Concurrency
In notebooks, you can run multiple Spark SQL commands in parallel. Control the concurrency by setting zeppelin.spark.concurrentSQL to true. The maximum number of commands that can be run concurrently is controlled by zeppelin.spark.sql.maxConcurrency, which is set to a positive integer. The default value of this parameter is 10.
Enabling Python 2.7 in a Notebook
If your cluster is running Python 2.6, you can enable Python 2.7 in a notebook as follows:
Add the following configuration in the node bootstrap script (node_bootstrap.sh) of the Spark cluster:
source /usr/lib/hustler/bin/qubole-bash-lib.sh qubole-hadoop-use-python2.7
Navigate to the Interpreter page. Under the Spark interpreter (
%spark), set thezeppelin.pyspark.pythonproperty to/usr/lib/virtualenv/python27/bin/python.After setting the property, restart the Spark interpreter. The default value of this setting is
python.