Understanding Spark Notebooks and Interpreters
QDS supports Spark Notebooks; the Spark cluster must be running before you can use them.
To use a Spark notebook, navigate to Notebooks from the main menu of the QDS UI. The topics under Notebooks provide more information about using Notebooks in QDS. Running Spark Applications in Notebooks provides more information on using a Spark Notebook.
Understanding Spark Notebook Interpreters
Note
For information about configuring and using interpreters in user mode, see Configuring a Spark Notebook and Using the User Interpreter Mode for Spark Notebooks.
You can create a Spark interpreter and define custom settings by clicking the Interpreter link near the top right
of the page. Notebooks support the spark interpreter among others; spark is a superset of the pyspark,
sparksql, and sparkscala interpreters. To see the list of available interpreter types, click Create and
then pull down the menu under Interpreters on the resulting page.
Generally, an interpreter name is not editable. You can specify Spark settings. Spark interpreters started by notebooks
have the specified settings. The default values are optimized for each instance type. While creating a new Spark
interpreter property, after selecting the interpreter, some settings are shown by default with description. You can
change these settings as required. One important setting is spark.qubole.idle.timeout. This setting is number of
minutes after which a Spark context shuts down, if no job has run in that Spark context.
Note
If you run a local process such as a Python or R command, the Spark cluster shuts down because Qubole does not interpret these actions as running a Spark job. Moreover, because Spark uses lazy evaluation, only actions and not transformations trigger a job. For more information on the difference between an action and a transformation, see the Spark for Data Engineers course on https://university.qubole.com.
This figure shows the default settings that get displayed after selecting the Spark interpreter.
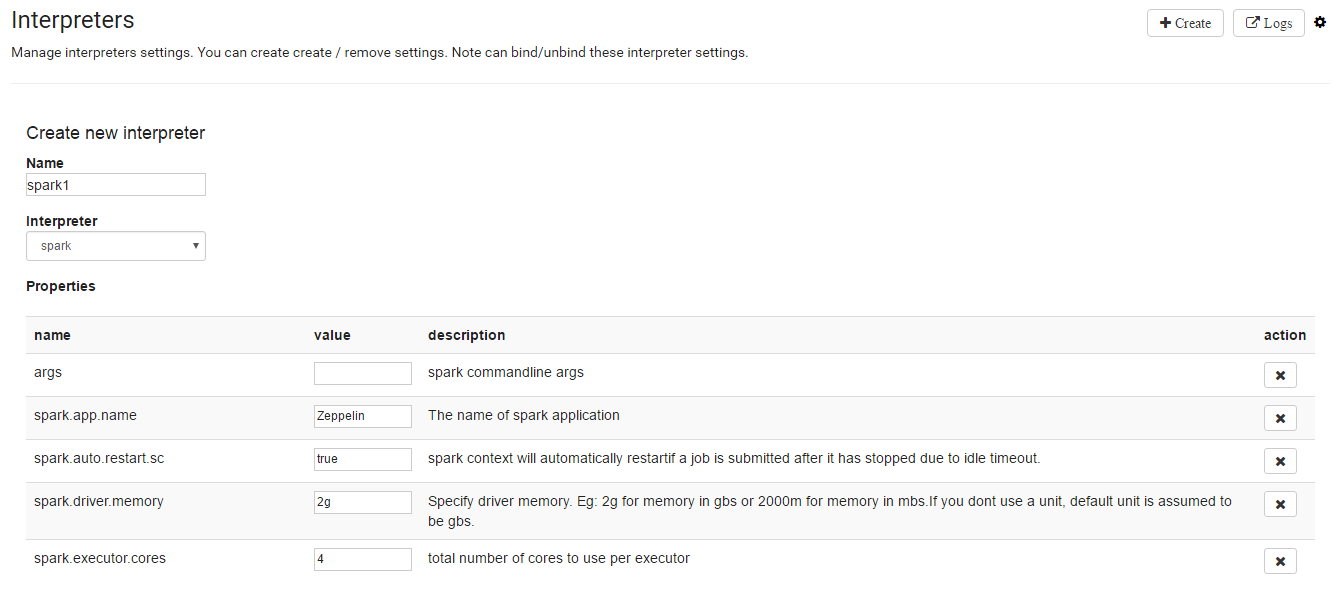
Qubole has simplified interpreter properties by setting default values for few of them and hiding them from the UI. In a new Spark interpreter, you can only see fewer set of properties. However, you can always override the value of the properties that are removed.
Note
Simplified interpreter properties for the existing Spark interpreters is not enabled for all users by default. Create a ticket with Qubole Support to enable this feature on the QDS account.
Running Spark Applications in Notebooks explains interpreters and how to associate interpreters with the notebooks.
Note
You can click the stop button on the Interpreters page to stop a Spark interpreter.
Binding an Interpreter to a Notebook
You must bind a notebook to use a specific interpreter.
On the Notebooks page, click on the Gear icon for interpreter binding.
On the Settings page, list of Interpreters are displayed as shown in the following figure.
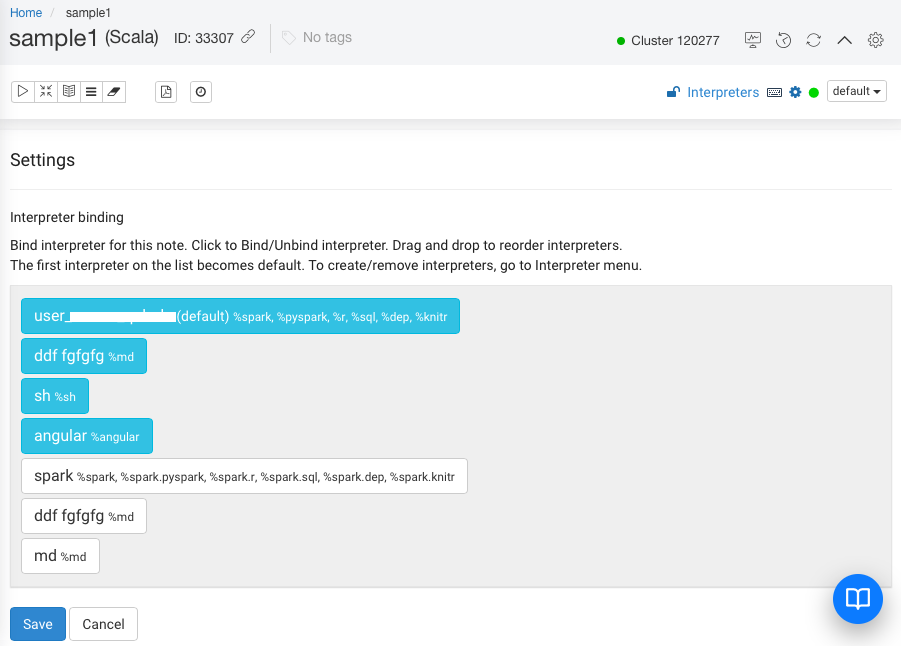
The first interpreter on the list is the default interpreter.
Click on any interpreter to bind it to the notebook.
Click Save.
Interpreter Operations
From the Interpreters page, you can perform the following operations on the Spark interpreters by using the corresponding buttons on the top-right corner against the Spark interpreters:
Edit the interpreter properties.
Stop the interpreter.
Restart the interpreter.
Remove the interpreter.
Access the log files.
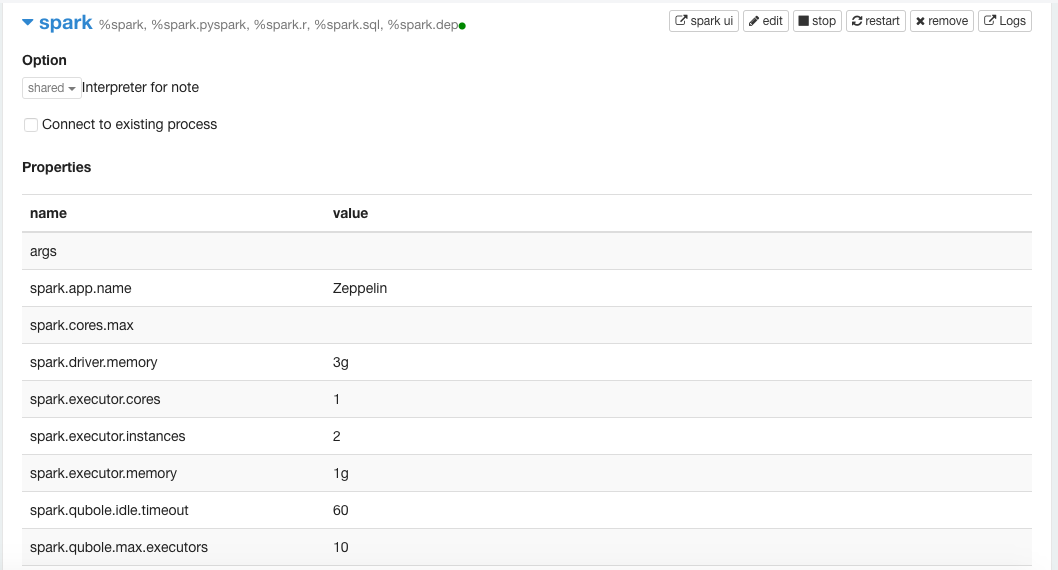
The following illustration displays a sample spark interpreter with the options.

Viewing the Spark Application UI in a Notebook
Qubole now supports viewing the Spark Application UI that shows a list of jobs for paragraphs run in a notebook.
Perform the following steps to view the Spark Application UI:
Navigate to the Interpreter page in a Spark Notebook.
Expand the interpreter and you can click the spark ui button on the top-right corner against the Spark interpreters as shown in the following figure.
Note
The Spark Application UI opens as a new popup. Disable the block pop up windows setting (if it is set) on a browser to see the Spark Application UI.
When Zeppelin starts, sparkcontext is not running by default. Therefore, clicking spark ui shows an alert dialog informing
that No application is running when Zeppelin just starts or gets restarted. Later, after a Spark application starts,
clicking spark ui directs to the Spark Application UI.
Seeing a Spark application that abruptly stops, in the Spark Application UI redirects you to the last-completed Spark job. Seeing a Spark application that is stopped explicitly, in the Spark Application UI also redirects you to the last-completed Spark job.
Note
In a cluster using Spot nodes exclusively, the Spark Application UI may display the state of the application incorrectly, showing the application as running even though the coordinator node, or the node running the driver, has been reclaimed by AWS. The status of the QDS command will be shown correctly on the Analyze page. Qubole does not recommend using Spot nodes only.
Viewing the Spark UI in Notebook Paragraphs
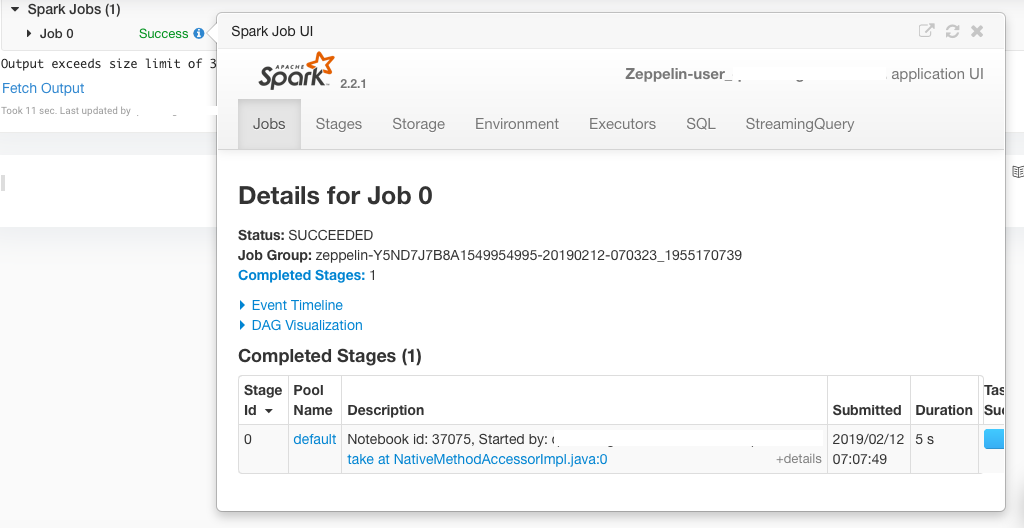
When you run paragraphs in a notebook, you can watch the progress of the job or jobs generated by each paragraph within the paragraph as shown in the following figure.

Expand Spark Jobs to view the status of the job. Click on the i info icon to open the Spark Application UI/Job UI.
A sample Spark Application UI is as shown in the following figure.
Using the Angular Interpreter
Qubole supports the angular interpreter in notebooks. Using the %angular interpreter and the HTML
code/JavaScript(JS) renders a custom UI. See Back-end Angular API
for more information.
Note
Unlike other type of interpreters, the Angular interpreter does not honor a property or a dependency that you add.
To run an HTML code/JS using the angular interpreter, perform the following steps:
Navigate to Notebooks on the QDS UI. Select the active notebook from the list on which you want to run the HTML code/JS.
Add the HTML code/JS with %angular in the beginning of the paragraph. For example, you can add this in a paragraph.
%angular <paragraph>Hello World</paragraph>
Run the paragraph and you can see the result on a successful execution. A sample result is as shown in the following figure.

Configuring Bootstrap Spark Notebooks and Persistent Spark Interpreters
An interpreter runs only when the command is run on the notebook. To avoid any issue that may occur due to an absence
of a running interpreter, Qubole supports a Spark interpreter (SI) that can be continuously run without any interruption.
Qubole automatically restarts such SI in case of driver crashes, manual stop of interpreter or programmatic
stop using sc.stop. Such an interpreter is called Persistent SI.
Note
Persistent Spark Interpreter is deprecated in Zeppelin 0.8 version.
Qubole supports a bootstrap notebook configuration in an SI. A bootstrap notebook runs before any paragraph or others using that associated SI, runs.
Configuring a Spark Bootstrap Notebook
Configure the bootstrap notebook feature in a notebook by adding the zeppelin.interpreter.bootstrap.notebook as the
interpreter property and add <notebook-id> as its value. <notebook-id> is the system-generated ID of that notebook,
in which the bootstrap notebook property is being set. On the UI, notebook ID is the read-only numerical value against
the ID text field when you try to edit the notebook or see notebook details.
See Viewing a Notebook Information and Configuring a Notebook for more information. In an opened notebook,
on top of all paragraphs, the ID is enclosed in brackets after the notebook name. For example,
if Notebook> NewNote(5376) is on the top of an opened notebook, then 5376 is the ID of the notebook with NewNote
as its name. See Tagging a Notebook and the explanation below for more illustrations.
In new notebooks, Qubole has set the value of zeppelin.interpreter.bootstrap.notebook to null.
The following figure shows the zeppelin.interpreter.bootstrap.notebook and zeppelin.interpreter.persistent with
the default values in a new notebook’s SI.
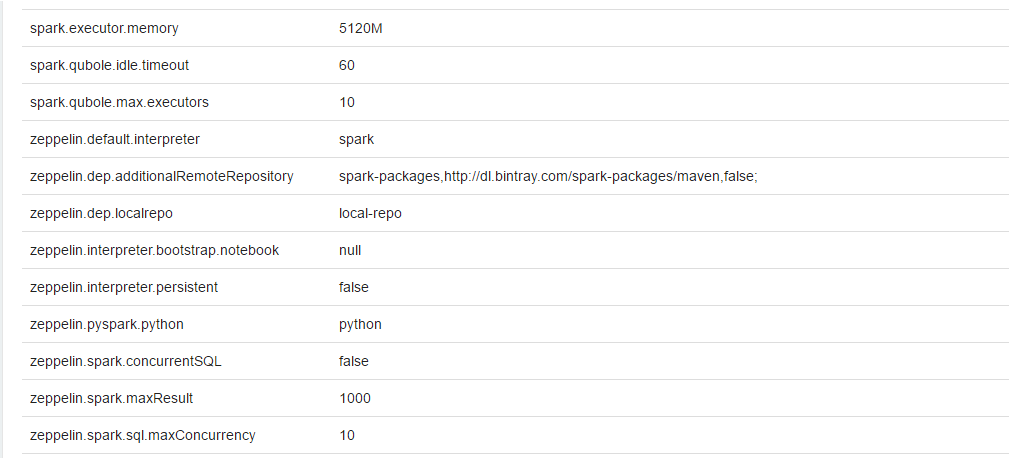
The following figure shows the zeppelin.interpreter.bootstrap.notebook and zeppelin.interpreter.persistent with the
enabled values in a notebook’s SI.
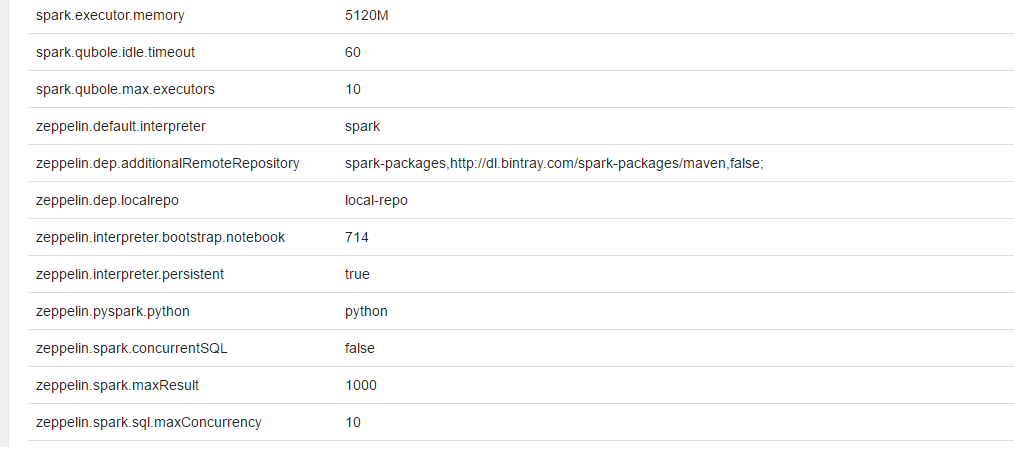
Configuring a Persistent Spark Interpreter
Note
Since a persistent SI is always running, the cluster with a persistent SI is never idle. Hence, that cluster never terminates automatically.
Configure a persistent SI in a notebook by adding the zeppelin.interpreter.persistent as the
interpreter property and add true as its value. (Refer to the above figures for the property and its value.)
In new notebooks, Qubole has set the value of zeppelin.interpreter.persistent in the SI to false.
The bootstrap notebook and persistent SI properties are independent of each other.
Understanding Examples
Example 1
Suppose if you want to automatically start an SI on a cluster start and also start the Hive thrift server under it. Using the node bootstrap and jobserver would prove to be tedious. Instead, you can use the bootstrap notebook and persistent SI features.
Example 2
When the Spark context (sc) restarts after going down due to idle timeout or any other such reason, you have to
manually restart the Hive server and load lot of tables in the cache. This can be avoided if you configure a persistent
SI property in the notebook.
Example 3
Using the bootstrap notebook and persistent SI features solves issues that can come up in a long-running streaming application written in an SI in Scala. You can write the bootstrap script in a way to handle checkpoint directories correctly.