Getting Started with the Qubole Cost Explorer
As part of the reporting and insights feature, data is uploaded to the cloud storage bucket. You can upload this data to:
The default location configured in your account settings: <defloc>/qubole_bi/v1/
The custom cloud storage bucket: <custom_storage_location>/qubole_bi/v1/
To upload to a custom cloud storage bucket, contact your account team.
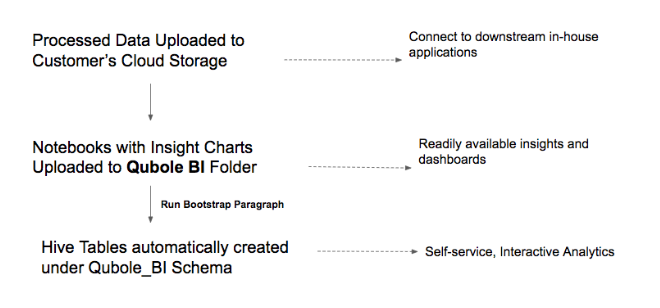
Notebooks with insights and charts are available in the Example tab > Qubole BI folder of Notebooks.
Let’s get started with the Qubole Cost Explorer.
Step 1. Copy the Notebook
Navigate to Notebook > Example tab > Qubole BI.
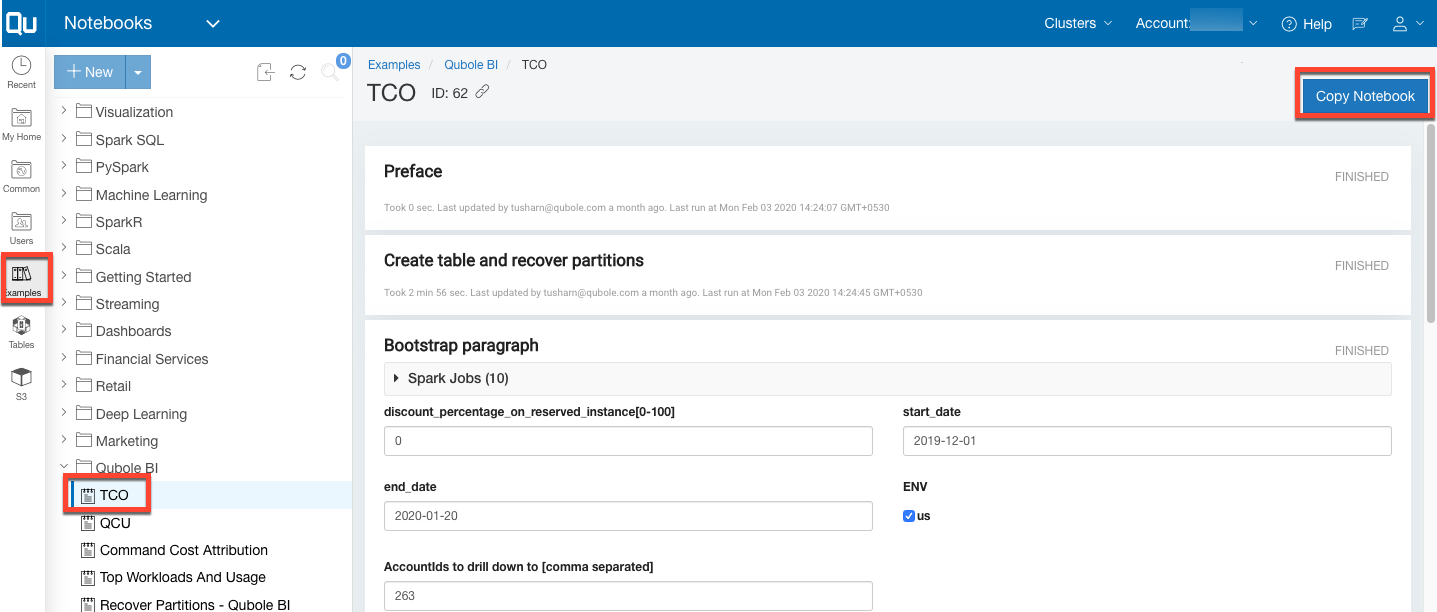
Copy the notebook.
Attach a specific Spark cluster to run it.
Note
The pre-built notebooks are Spark notebooks and require a Spark cluster to run.
Step 2. Run the Create Tables and Recover Partition Paragraph
Every shared notebook has a mandatory Create tables and recover partition first paragraph. Run this paragraph before running others as this checks for the presence of the relevant Hive tables. If these are not present, the system automatically creates them using the data available in the cloud storage. The tables are created under the Qubole_BI_<Qubole_environment>_<Qubole_Account_Id> schema. For more information on the tables, see the Data Dictionary.
Note
As this paragraph creates the tables, ensure that this notebook is first run by users having the relevant permissions for creating tables in the Hive Metastore.
Bootstrap Paragraph for Creating Tables
First Time Execution
When this paragraph is executed for the first time, it automatically reads the data available in the cloud storage (S3, GCS, etc.) and creates Hive tables for self-service execution.
Successive Execution
When this paragraph is executed for successive analysis, it automatically refreshes the table and updates it with the latest data.
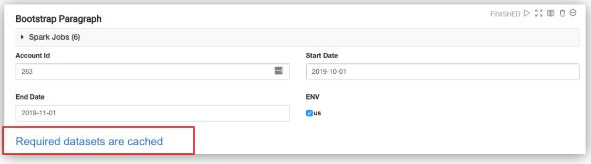
Bootstrap Paragraphs for Data Cache
The pre-built notebooks provided by Qubole allow users to analyze the data across different dimensions through the input fields. To facilitate interactive analytics, the system caches the filtered dataset in memory and ties it to the lifecycle of the Spark Application that is launched for that particular notebook.
Every time the Spark Application is terminated, the data is evicted. As a result, if you try to run successive paragraphs, the system throws an error. Before running the paragraphs that contain the insights, Qubole recommends you run the bootstrap paragraph every time you restart the Spark Application.
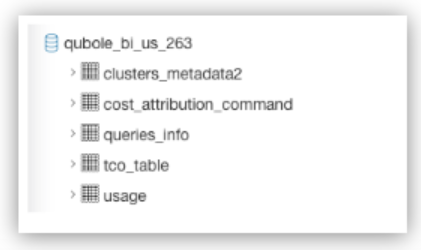
Once the bootstrap paragraphs are run, QDS automatically creates Hive tables under the <qubole_bi_environment_account_id> schema.
qubole_bi |
Denotes that this schema is related to Cost Explorer tables. |
environment |
Denotes the environment to which your Qubole deployment belongs. |
account_id |
Denotes the account ID to which all the data across multiple Qubole accounts has been consolidated. |
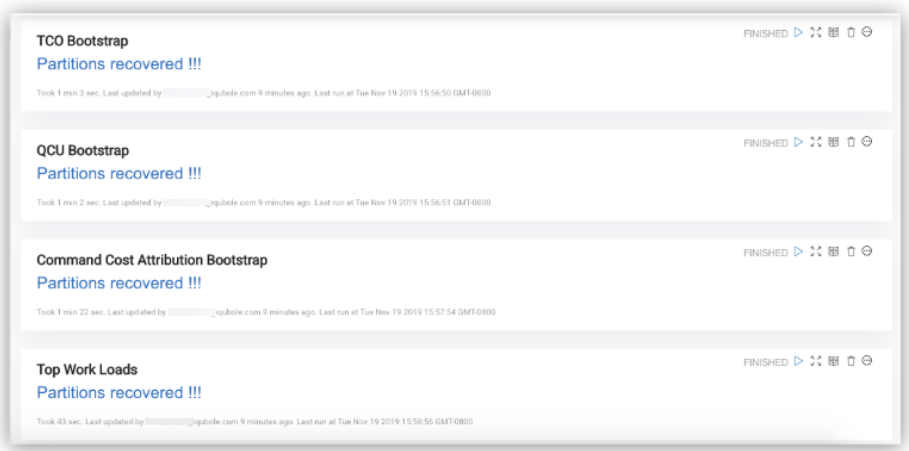
Step 3. Schedule the Table Refresh
As data is uploaded to the cloud storage daily, you must recover the partitions daily too. This ensures that the table is refreshed and always has the latest data. Qubole recommends you schedule this for periodic runs (daily).
You can do this in two ways:
By using the Recover Partitions - Qubole BI Notebook
This notebook schedules jobs that run on a daily basis, refreshes tables, and ensures that the latest data is available for Qubole Cost Explorer analysis.
Navigate to the Notebooks > Example Tab > Qubole BI folder.
Copy the Recover Partitions- Qubole BI notebook and schedule it to run on a daily basis.
For more details on how to schedule a notebook, see How to schedule a notebook.
By scheduling a Custom Command
Alternatively, you can build your own recover partitions command and schedule it to run on a periodic basis through the Qubole Scheduler or through the Qubole Airflow.
Important
Data is scheduled to be uploaded to your cloud storage bucket by 2 PM UTC daily. Qubole recommends you run the partition recovery after the data upload is completed. This ensures that all relevant tables are updated and contain the latest data for any self-service SQL analytics.
As more insights are available for a particular notebook, Qubole may (periodically) update the notebooks with new paragraphs or change existing paragraphs. The latest notebooks are available in the Notebooks > Example Tab > Qubole BI folder.