Running a Simple Spark Application
This page is intended to guide a new user in running a Spark application on QDS. For more information about composing and running Spark commands from the QDS UI, see Composing Spark Commands in the Analyze Page.
Note
Executing a Spark Application from a JAR using QDS describes how to execute a Jar containing a simple Spark application from an AWS S3 location.
Before You Start
You must have an active QDS account; for instructions on creating one, see Managing Your Accounts. Then sign in to the QDS UI.
Submitting a Spark Scala Application
After signing in, you’ll see the Analyze page. Under the History tab, you can see all the queries that have been run so far. If you have just signed in for the first time, History contains some sample commands.
Proceed as follows to run a Spark command. In this example we’ll be using Scala.
Click Compose from the top menu.

Select Spark Command from the Command Type drop-down list.
You see an editor that can be used to write a Scala Spark application. Qubole also allows you to change the language setting to write a Python, Command-line, SQL, or R Spark application. See the following topics for more information:
The supported languages to write a Spark application are as shown in the following figure.
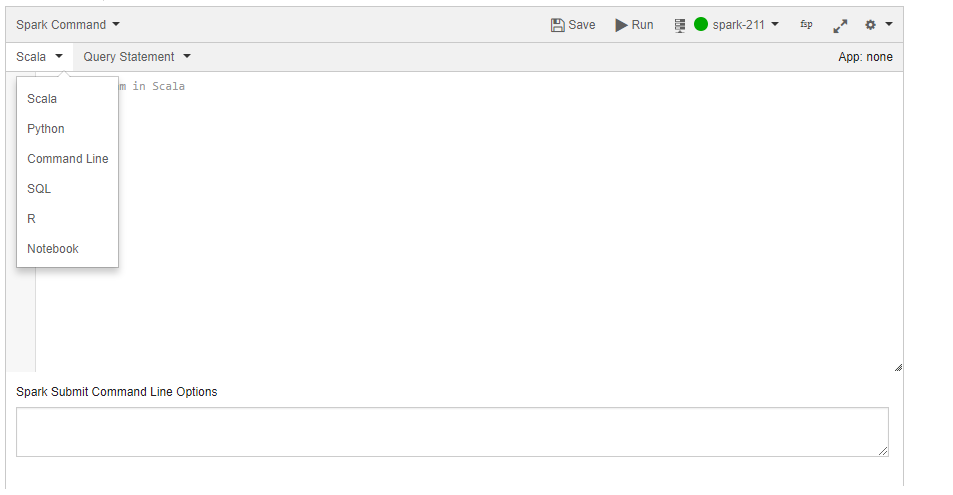
Let us start with a simple Scala Spark application. Type the following text into the editor.
import org.apache.spark._ object FirstProgram { def main(args : Array[String]) { val sc = new SparkContext(new SparkConf()) val result = sc.parallelize(1 to 10).collect() result.foreach(println) } }
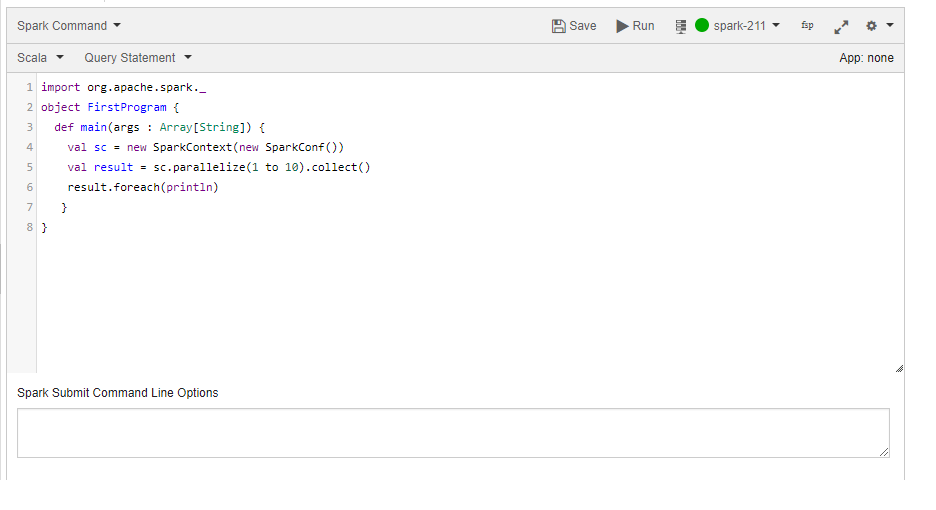
Execute this program by clicking Run at the top of the editor. Congratulations! You have run your first Spark application using QDS.
By default, Qubole provides some configured clusters to each account, which includes a Spark cluster. Qubole manages the complete lifecycle of the cluster. When you submit a Spark command, it automatically brings up the Spark cluster. When the cluster is idle for sometime, it terminates the cluster. For more details, see Introduction to Qubole Clusters.
Also, note that the above action brings up the cluster, which takes a few minutes to start. All subsequent queries holds on to the same cluster.
Viewing the Logs and Results
The Logs and Results tabs are available just below the query composer. The pane that is to the left of the query composer is for History, which contains all queries run through Qubole. You can check the logs and results of any previously submitted query.
Note
You can access a Spark job’s logs even after the cluster on which it was run is terminated.
Accessing Data Sets in S3
In a cloud-based model, data sets are typically stored in S3 and are loaded into Spark. Here is the familiar example of word count against a public data set accessible from all Qubole accounts.
import org.apache.spark._
import org.apache.spark.SparkContext._
object s3readwrite {
def main(args: Array[String]) {
val sc = new SparkContext(new SparkConf())
val file = sc.textFile("s3://paid-qubole/default-datasets/gutenberg/pg20417.txt")
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
.collect()
counts.foreach(println)
}
}
To start accessing data in your S3 buckets, navigate to Control Panel > Account Settings > Storage Settings and enter AWS S3 access and secret keys.
Passing Arguments to Spark Application
Let us consider parameterizing the S3 location in the previous application and pass it as an argument. Here is an example of how to do it.
import org.apache.spark._
import org.apache.spark.SparkContext._
object s3readwrite {
def main(args: Array[String]) {
val sc = new SparkContext(new SparkConf())
//taking first argument as location in s3
val file = sc.textFile(args(0))
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
.collect()
counts.foreach(println)
}
}
Now, pass the S3 location in the Arguments for User Program text box. Try the same public location, s3://paid-qubole/default-datasets/gutenberg/pg20417.txt. In this way, the program can take in any number of arguments.
Executing a Spark Application from a JAR using QDS
You can run a Spark application that is within a JAR on an AWS S3 location.
Perform the following steps:
Copy the JAR file containing the Spark application to an AWS S3 location.
Run this command specifying the AWS S3 bucket location of that JAR file.
Note
The syntax below uses https://api.qubole.com as the endpoint. Qubole provides other endpoints to access QDS that are described in Supported Qubole Endpoints on Different Cloud Providers.
qds.py --token=API-TOKEN --url=https://api.qubole.com/api sparkcmd run --cmdline "/usr/lib/spark/bin/spark-submit --class org.apache.spark.examples.SparkPi s3://<your bucket location>/jars/spark-examples.jar"
The command runs successfully to give a successful sample output as shown below.
Pi is roughly 3.1371356856784285
Composing Spark Commands in the Analyze Page describes how to compose a command using the QDS UI’s Analyze page’s query composer.
Submit a Spark Command describes how to submit a Spark command as a REST API call.
Using Notebooks
To run Spark applications in a Notebook, follow this quick-start guide, Running Spark Applications in Notebooks.