Running Spark Applications in Notebooks
You can run Spark Applications from the Notebooks page of the QDS UI. When running Spark applications in notebooks, you should understand notebooks, how to associate interpreters with notebooks, how to run concurrent commands, and how to set the context.
Log in to QDS with your username and password. Navigate to the Notebooks page.
Understanding Notebooks
You can create any number of new notebooks. Notebooks data is synced and persisted in cloud storage (for example S3) regularly. Notebooks are associated with a cluster, so notebooks from cluster A can not be accessed by cluster B.
See Notebooks for more information on Qubole’s Notebooks. For more information, see:
Understanding Spark Notebooks and Interpreters describes Spark interpreters.
Configuring a Spark Notebook describes the configuration associated with the Spark notebook.
Running Spark Notebooks in a Schedule describes how to schedule notebooks using the Qubole Scheduler
Run a Notebook describes how to run a notebook through a REST API call.
Associating Interpreters with Notebooks
Spark Interpreters are associated with notebooks by default. However, if you want to use any user interpreter then you must associate the interpreter with the notebook. Interpreters are started on demand when required by notebooks.
On the Notebooks page, click on the Gear icon.

On the Settings page, list of Interpreters are displayed as shown in the following figure.
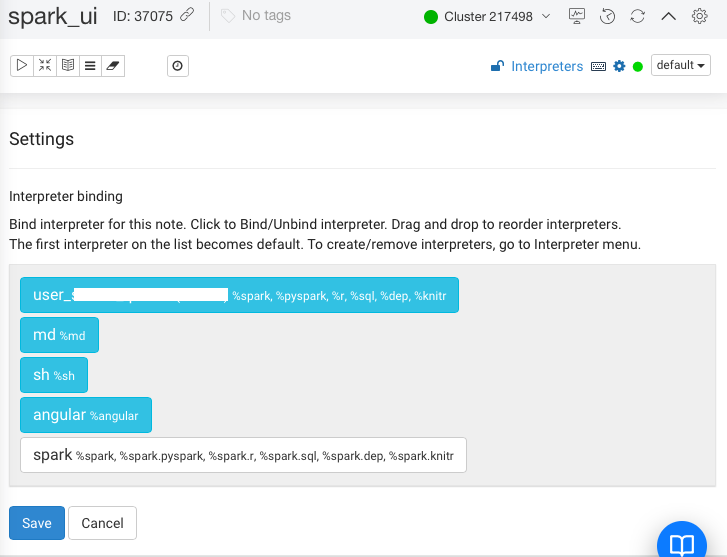
The first interpreter on the list is the default interpreter.
Click on the required interpreter to associate with the notebook.
Click Save.
Running Concurrent Spark Commands
You can run multiple Spark SQL commands in parallel.
On the Notebooks page, click Interpreters.
For the required interpreter, click on the corresponding edit button.
Set the following properties:
zeppelin.spark.concurrentSQL=true
zepplin.spark.sql.maxConcurrency=number of concurrent commands to be runCreate multiple paragraphs with Spark SQL commands and click the Run icon on the left side to run all the paragraphs.
All the paragraphs run concurrently.
Using SparkContext, HiveContext and SQLContext Objects
Similar to a Spark shell, a SparkContext (SC) object is available in the Notebook. In addition, HiveContext is also available in a Notebook if you have to set the following configuration to true in interpreter settings:
zeppelin.spark.useHiveContext
If this configuration is not set to true, then SQLContext is available in a Notebook instead of HiveContext.