Reading from Hive ACID Tables
You can read the Hive ACID tables through Scala and SQL from the Analyze or Notebooks UI.
Reading Hive ACID Tables through Scala
Depending on whether you want to read the Hive ACID tables through Scala from the Analyze UI or Notebooks UI, perform the appropriate actions:
Reading from the Analyze UI
Navigate to the Analyze page and click Compose.
Select Spark Command from the Command Type drop-down list.
By default, Scala is selected.
Compose the Spark application. When composing, specify the Hive ACID data source by short names using the
.format("HiveAcid")format. Useformat("HiveAcid").options(Map("table", "table name"))for read operations andformat("HiveAcid").option("table", "<table name>"")for write operations.The following example shows a sample Scala code.
val df = spark.read.format("HiveAcid").options(Map("table" -> "db.acidtbl")).load() df.collect()
Specify the JAR file in the using Spark Submit Command Line Options in the the query editor as show below.
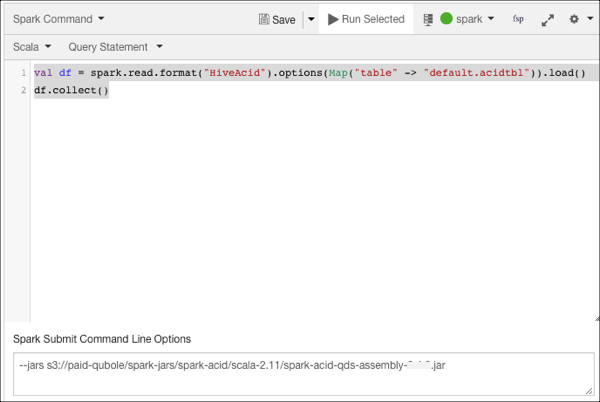
Click Run.
Reading from the Noteooks UI
Navigate to the Interpeter settings.
Specify the JAR file in the spark.jars property as shown in the following figure.
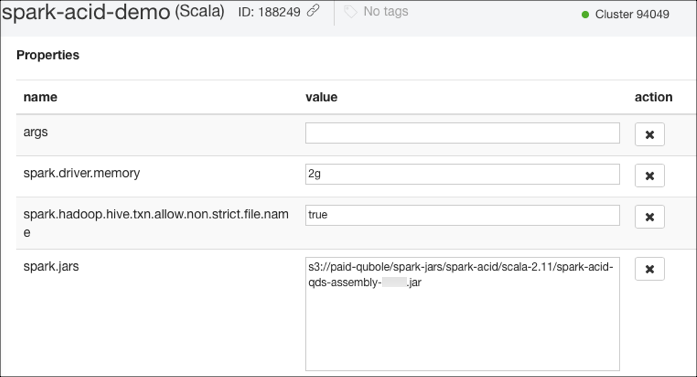
For more information about editing the interpreter settings, see Using the User Interpreter Mode for Spark Notebooks.
Compose the Spark application in a paragraph. When composing, specify the Hive ACID data source by short names using the
.format("HiveAcid")format. Useformat("HiveAcid").options(Map("table", "table name"))for read operations andformat("HiveAcid").option("table", "<table name>"")for write operations.Run the paragraph.
Reading Hive ACID Tables through SQL
For reading the Hive ACID tables through SQL, you should specify the SparkSession extensions framework to add a new Analyzer rule (HiveAcidAutoConvert) to Spark Analyzer. You can specify the SparkSession extension framework while performing the following tasks:
Creating a new Spark session
Running commands on the Analyze UI. Specify the
--conf spark.sql.extensions=com.qubole.spark.hiveacid.HiveAcidAutoConvertExtensionconfiguration as a command line option.Running notebook. Specify the configuration in the Interpreter settings of the notebook.
Alternatively, you can also specify the spark.sql.extensions=com.qubole.spark.hiveacid.HiveAcidAutoConvertExtension configuration as a Spark override configuration at a cluster level. For more about Spark override configurations, see Overriding the Spark Default Configuration.
Depending on whether you want to read the Hive ACID tables through SQL from the Analyze UI or Notebooks UI, perform the appropriate actions:
Reading from the Analyze UI
Navigate to the Analyze page and click Compose.
Select Spark Command from the Command Type drop-down list.
By default, Scala is selected. Select Python.
Specify the JAR file in the Spark Submit Command Line Options in the the query editor.
Specify the SparkSession extensions framework in one of the following ways:
Initialize the SparkSession when creating a new Spark session as mentioned below:
val spark = SparkSession.builder() .appName("Hive-acid-test") .config("spark.sql.extensions", "com.qubole.spark.datasources.hiveacid.HiveAcidAutoConvertExtension") .enableHiveSupport() .getOrCreate() spark.sql("select * from db.acidtbl")
Specify the configuration in the Spark Submit Command Line Options in the the query editor as show below.
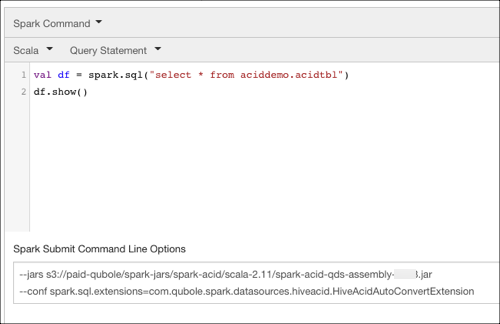
Click Run.
Reading from the Noteooks UI
Navigate to the Interpeter settings.
Specify the JAR file in the spark.jars property and the configuration
com.qubole.spark.datasources.hiveacid.HiveAcidAutoConvertExtensionin the spark.sql.extension property as shown in the following figure.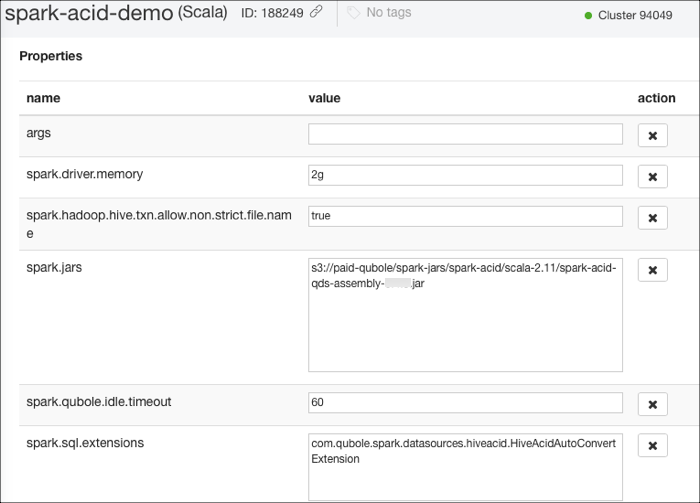
For more information about editing the interpreter settings, see Using the User Interpreter Mode for Spark Notebooks.
Compose the Spark application in a paragraph.
Run the paragraph.