Data Import and Export Command Using Hadoop2 Cluster
Over time, it is observed that the vast majority of users prefer to run DBImport/Export commands in their own account and cluster for the following reasons:
To avoid data flow through Qubole.
Customer-owned clusters can be upgraded faster.
To reduce communication cost by running the clusters in the same region as the S3 bucket. This is not possible with Qubole Operated Cluster (QPC) which runs in a fixed region.
It is recommended for you to execute DBImport/DBExport operations on your own cluster. But you can still create new
new DBImport/Export command using QPC until 10th Jan, 2020 and continue to use it until 10th February, 2020. After 10th
February, 2020, QPC will become unavailable on api.qubole.com and us.qubole.com.
Migrating Commands
Qubole recommends migrating jobs successfully before deprecation timelines to avoid any adverse impact on commands.
You can migrate the command types listed below:
Data Import and Data Export Commands - to migrate these commands through the Qubole UI, perform these steps:
Navigate to Workbench (beta)/Analyze.
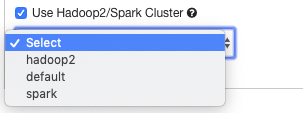
In the query composer for a data import or data export command, choose Use Hadoop 2/Spark Cluster. Pull the drop-down list, select **Hadoop 2 cluster. The following figure illustrates the UI option.
To migrate commands through the REST API, you must enable
use_customer_clusterby setting it totrueand pass the Hadoop cluster’s label as a value to thecustomer_cluster_labelparameter. For more information, see Submit a DB Export Command and Submit a DB Export Command.Workflow Command: For a workflow command, subcommands run through a common cluster. If there is a data import and data export sub commands under the workflow command, then follow the same steps as mentioned above under Data Import and Data Export Commands.
Scheduled Jobs: You should edit the scheduled jobs that contain data import and data export commands and select the Hadoop cluster as described above. After you select the cluster, the upcoming scheduled jobs would run on the Hadoop cluster.