Visualizing Spark Dataframes
You can visualize a Spark dataframe in Jupyter notebooks by using the display(<dataframe-name>) function.
Note
The display() function is supported only on PySpark kernels. The Qviz framework supports 1000 rows and 100 columns.
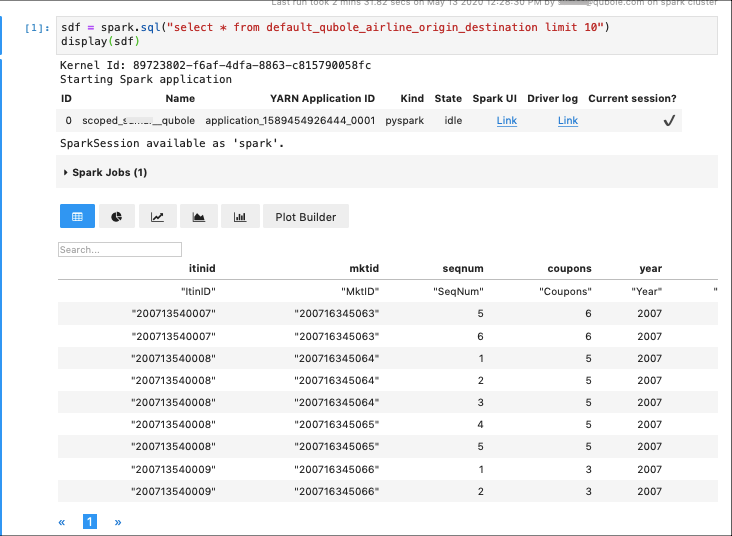
For example, you have a Spark dataframe sdf that selects all the data from the table default_qubole_airline_origin_destination. You can visualize
the content of this Spark dataframe by using display(sdf) function as show below:
sdf = spark.sql("select * from default_qubole_airline_origin_destination limit 10")
display(sdf)
By default, the dataframe is visualized as a table.
The following illustration shows the sample visualization chart of display(sdf).
You can click on the other chart options in the Qviz framework to view other visualization types and customize the chart by using the Plot Builder option. For more information, see Using Qviz Options.